story of my life
過去の蓄積を見るために書く日記.

AivisSpeech用の自分の声ベースモデルを作ろうとしてStyle-Bert-VITS2
文字数[719文字] この記事は1分54秒で読めます.
おはようございます.AivisSpeech用の自分の声ベースモデルを作ろうとしてStyle-Bert-VITS2を頑張る.事前に自分の声を12本録音してた奴をOpenAIが提供しているopenai-whisperで文字起こしを行いました.そのデータを元にStyle-Bert-VITS2の配下にあるTrain.batを叩くとブラウザが立ち上がる.何処にデータセットを置かないいけないかなども記載されている.
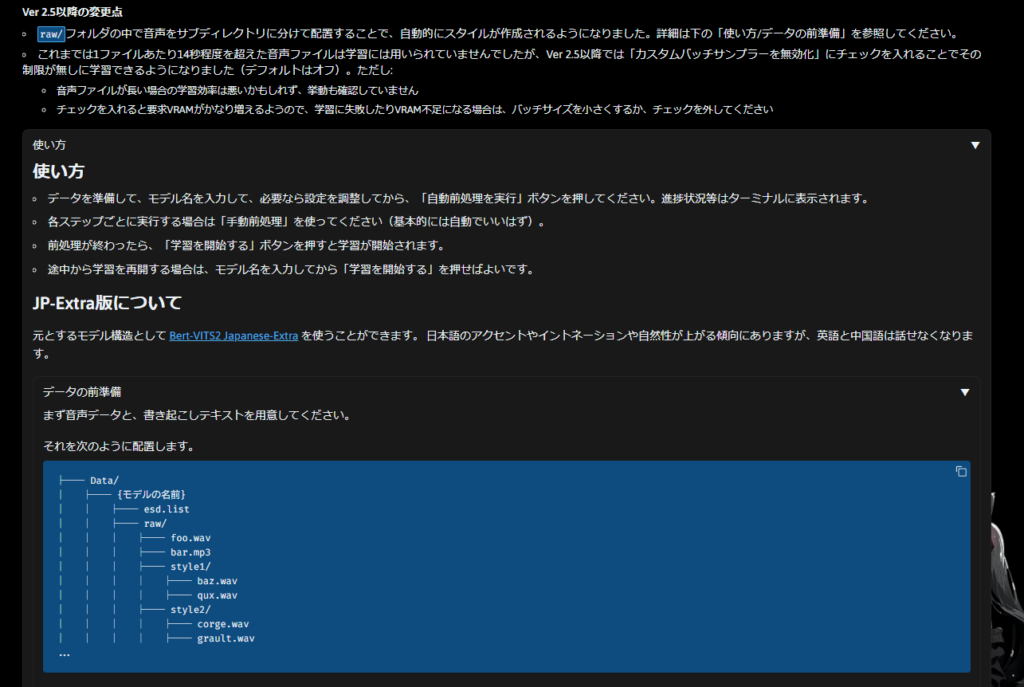
その場所にデータを配置します.配置後、上から順番に実行していけば学習モデルが生成されます、生成されたモデルをONNX形式に変換しその後aivmx形式しないとAivisSpeechでは使用できないらしい.変換コマンドはこちら、やり方はこの方が記載されているので参照ください.
git checkout dev
pip install onnx
pip install onnxsim
pip install accelerate
python convert_onnx.py --model 【SVBS2のモデルフォルダ】onnxに変換後、AivisSpeechの公式サイトのコンバーターサイトで変換するとaivmx形式が落ちてきます(ダウンロード).それをAivisSpeechアプリの設定から読み取ればOK!
結構長い手順ですが、これで自分の声の音声合成が出来ます.それで作ったのがこの音源です、雑音が入っているのはセミがなく中で録音した音声を学習させたからこんな感じになっています.
追伸:雑音を除去しました.下記は雑音を除去したものになります.
明日へ続く





3213番目の投稿です/824 回表示されています.
中の人🏠️
AIによるおすすめ記事
 著者名
@taoka_toshiaki
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
コンバーターサイト, セミ, ダウンロード, ブラウザ, モデルフォルダ, 事前, 何処, 変換コマンド, 奴, 学習モデル, 形式, 本録音, 追伸, 配下, 長い手順, 雑音, 音声, 音声合成, 音源, 順番,
コメントを残す