2022.10.05 文字数カウントは奥が深いよ。日本語より𓅇エジプト😇 #javascript #code #プログラミング #unicode おはようございます、先日(日曜日のこと)は久しぶりに本屋さん巡りしていました😋。本屋📖は良いですね落ち着きます。 さて、文字コードのカウントは奥が深いなって話を記載していきます。人目線からすれば文字をカウントするという至 […]
2022.06.12 面白い事をしている人。発見することが楽しいだろうな!!!。𒁠 おはようございます。この頃、睡眠時間、8時間確保を頑張りたいと思っています。 大西拓磨さんは、一年前(2022年)ぐらいにTVにも出演されてみたいですが、そこは割愛して。unicodeで面白いことをしているのが凄いな、自 […]
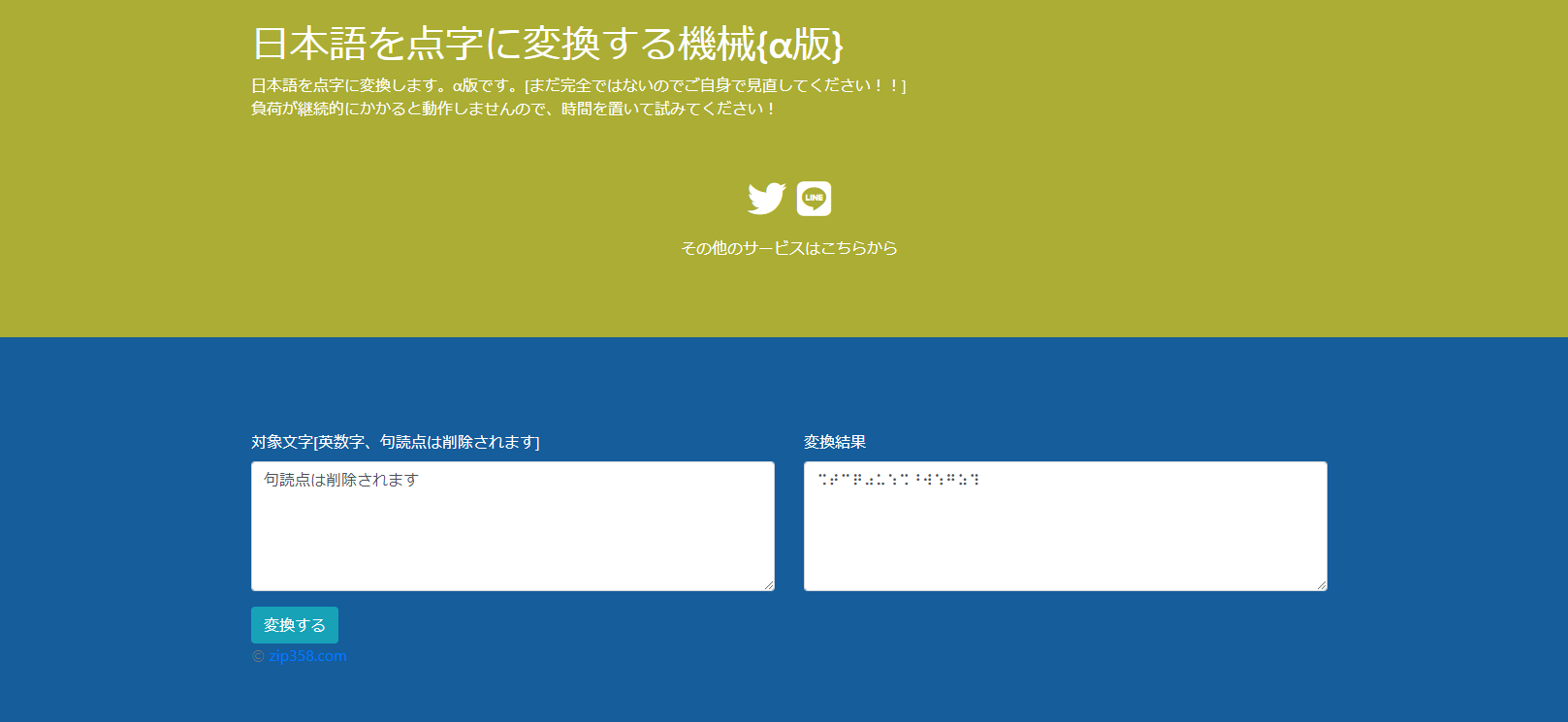
2021.10.15 日本語を点字に変換する機械?ツールを作りましたよ。人の役に立つかは?? 昨日は寝苦しい夜でして寝たり起きたりを繰り返しました。本日は熟睡できたら良いのですがね。 さて、今日は日本語を点字に変換する機械?ツールを作りましたよ。です・・・。今日のお昼ぐらいから取り掛かりました。点字のUnicod […]
2017.07.14 文字化けがモヤモヤした件:Unicodeめ!!とか機種依存文字とかの話。 文字化けがモヤモヤした件:Unicodeめ!!とか機種依存文字とかの話。会社でこちらの件でモヤモヤして最終的に解決できたのだけどなんだか腑に落ちないので自宅に帰って文字化けの検証をしてみました。勤めている会社はサイトコピ […]