@Blog
日常日誌からプログラムやYOUTUBER紹介、旅日記まで日々更新中です。

目が覚めてから大体1時間ぐらいPCを付けてぼーっとしている時間がある
2025.06.27
おはようございます.昨日はデススト2の発売日でした、まだ購入はしていません.
さて自分には目が覚めてから大体1時間ぐらいPCを付けてぼーっとしている時間がある、だいぶ前からだけど目が覚めてはいるけど、脳が回転していない時間帯があってその時間帯に何かしても頭に入ってこないので、ブログを書いたりXを見たりして早朝を過ごしている.
一時間ぐらい経過すると犬の散歩に連れて行く、そこで寝ぼけている脳が通常モードに切り替わる感じです.朝活している訳でもないだけども朝にタスクを消化している感じですね.
本なんかは朝食後、目を通したりしています.
リモートワークなので通勤がないので、朝食後から仕事までの時間を使えるのはメリットですね.こういう時間の使い道をリモートワークではない人が出来るようになるまでには、あと10年以上掛かると思います.
10年も経過すると自動運転車が普及しているようになると思うのでそれまではリモートワークの特権かと思います.
因みに自分は4時起きが基本です、寝るのもその分早いのです、7時間は睡眠時間に当てています.こういうリズムになったのは結構、犬の散歩という事柄が大きく影響しています.
明日へ続く
 著者名
@taoka_toshiaki
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
あと, それ, タスク, デススト, ブログ, メリット, モード, よう, リズム, リモート, ワーク, 事柄, 仕事, 以上, 使い道, 回転, 基本, 大体, 影響, 感じ, 散歩, 早朝, 明日, 昨日, 時間, 普及, 朝食, 消化, 特権, 発売, 睡眠, 経過, 自分, 自動, 購入, 通勤, 通常, 運転,

AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでも.
2025.06.22
おはようございます.AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでもなくローカルPCでそこら辺に落ちているLlamaモデルを持ってきてチューニングすれば何とかなるじゃねぇという思いに至った.
実はあなたの手元にあるPCと、そこら中に「落ちている」オープンソースのAIモデル、特にLlama 3があれば、十分記事が生成できるんです。
ローカルAI記事生成は、もはや夢物語じゃない
「AIで記事生成」と聞くと、SFのような世界や、大企業だけが使える特権のように感じるかもしれません。しかし、今は違います。オープンソースの強力な言語モデル、特にMetaが公開したLlama 3の登場は、この常識を大きく覆しました。
Llama 3は、その性能の高さにもかかわらず、誰でも無料で利用できるという点が最大の魅力です。さらに、80億パラメータの8Bモデルであれば、最新のゲーミングPCとまではいかなくとも、ある程度の性能を持つPCであれば十分に動作します。これにより、高額なクラウドサービスを利用せずとも、自分のPCでAI記事生成の環境を構築することが現実的になりました。
なぜLlama 3があなたのPCと相性抜群なのか?
Llama 3がローカルPCでの記事生成に適している理由はいくつかあります。
- 完全無料のオープンソース: 利用に費用がかからないため、予算を気にせずAIを試したり、本格的に導入したりできます。
- 選べるモデルサイズ: Llama 3には様々なサイズのモデルがあり、PCのスペックに合わせて選べます。特に8Bモデルは、個人利用に最適なバランスを持っています。
- 活発な開発者コミュニティ: 世界中の開発者がLlama 3を使った新しいツールや効率的なチューニング方法を日々共有しています。困ったときには助けを借りられる心強い味方です。
- 「量子化」でさらに軽量に: モデルのサイズを大幅に小さくする「量子化」という技術を使えば、より少ないメモリでLlama 3を動かせるようになります。これにより、より多くのPCで利用の道が開けます。
あなたのPCを「記事生成マシン」に変える秘訣
もちろん、いきなりプロのライター並みの記事をAIに書かせるのは難しいかもしれません。しかし、ちょっとした工夫で「何とかなる」レベルの記事生成は十分に可能です。
- 少量のデータでファインチューニング: 大量の記事データは不要です。あなたが書きたい記事のテーマやスタイルに合った、質の良い記事を数十〜数百程度集めてLlama 3を学習(ファインチューニング)させれば、その分野に特化した記事生成能力が格段に向上します。
- プロンプト(指示文)の工夫: AIへの「指示の出し方」は非常に重要です。具体的で明確なプロンプトを与えることで、チューニングが完璧でなくても、驚くほど質の高い記事が生成できます。これはまるで、優秀なアシスタントに的確な指示を出すようなものです。
- 効率的な学習方法の活用: 「LoRA(Low-Rank Adaptation)」のような効率的なファインチューニング手法を使えば、少ないGPUメモリでも短時間でモデルを特定のタスクに最適化できます。
あなたの創造性が、今、AIで加速する
かつては一部の専門家や企業にしか手の届かなかったAIによる記事生成が、今やあなたのPCで実現できる時代になりました。これはまさにAI技術の「民主化」です。
とまぁそういう訳なので何とかしてみますが、ファインチューニングにどれぐらい時間がかかるのかが未知数だったりする.
ファインチューニングPythonコード
以下のPythonコードは、Llama 3モデルをロードし、提供されたテキスト記事でファインチューニング(LoRA使用)を実行し、結果を保存します。 上記の入力値は、このコードに自動的に反映されます。 このコードをPythonファイル(例: `finetune_llama.py`)として保存し、実行してください。
import os
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training, TaskType
# GPUの利用可能性を確認
print("GPUが利用可能か確認中...")
if not torch.cuda.is_available():
print("GPUが見つかりません。Fine-tuningにはGPUが強く推奨されます。")
# GPUがない場合は、ここでスクリプトを終了するか、CPUモードで続行するか選択できます。
# exit("GPUがないため終了します。")
else:
print(f"GPUが利用可能です: {torch.cuda.get_device_name(0)}")
# --- 1. モデルとトークナイザーのロード ---
# Llama 3モデルのパスを指定します。Hugging Faceのモデル名(例: "meta-llama/Llama-3-8B")
# またはローカルにダウンロードしたモデルのパスを指定してください。
MODEL_NAME = "meta-llama/Llama-3-8B" # ユーザーが入力したパスがここに挿入されます
print(f"モデルとトークナイザーをロード中: {MODEL_NAME}")
# 4bit量子化設定 (GPUメモリの節約に役立ちます)
# bnb_4bit_compute_dtypeは、Ampere以降のNVIDIA GPUに推奨されるbfloat16を使用しています。
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4", # NF4 (NormalFloat4) 量子化タイプ
bnb_4bit_compute_dtype=torch.bfloat16
)
# トークナイザーをロード
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
# Llama 3はデフォルトでbos_tokenを付与しないことがあるため、明示的に追加。
# また、padding_side='right'はLlamaモデルに推奨される設定です。
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# モデルをロードし、量子化設定を適用し、自動的にGPUにマッピングします。
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=bnb_config,
device_map="auto", # 利用可能なデバイス(GPU)に自動的にモデルを分散
trust_remote_code=True # リモートコードの実行を許可
)
print("モデルロード完了。")
# k-bit学習用にモデルを準備 (PEFTライブラリのため)
# gradient_checkpointingを有効にすることで、メモリ使用量をさらに削減できます。
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
print("k-bit学習用にモデルを準備しました。")
# --- 2. データセットの準備 ---
# あなたのテキスト記事ファイルが格納されているディレクトリを指定します。
# 例: 'your_article_data/' の中に 'article1.txt', 'article2.txt', ... と置かれている場合
DATA_DIR = "./your_article_data/" # ユーザーが入力したパスがここに挿入されます
print(f"データセットをロード中: {DATA_DIR}")
# 'text'形式でデータセットをロードします。指定されたディレクトリ内のすべての.txtファイルを読み込みます。
# 各ファイルが1つのエントリとして扱われます。
try:
dataset = load_dataset('text', data_files={'train': os.path.join(DATA_DIR, '*.txt')})
print(f"データセットのサンプル数: {len(dataset['train'])}")
except Exception as e:
print(f"データセットのロード中にエラーが発生しました。ディレクトリとファイル形式を確認してください: {e}")
exit("データセットロード失敗。")
# データセットをトークン化する関数
# 長い記事をモデルの最大入力長に分割します。
def tokenize_function(examples):
# Llama 3の最大入力長は通常8192ですが、お使いのGPUのVRAMに合わせて調整してください。
# ここでは一般的な値として2048を設定しています。
max_length = 2048
# truncate=Trueで最大長を超えるテキストを切り捨てます。
return tokenizer(examples["text"], truncation=True, max_length=max_length)
# データセットをトークン化します。
# num_procはCPUコア数に応じて並列処理を行い、処理を高速化します。
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
num_proc=os.cpu_count(),
remove_columns=["text"] # 元のテキスト列は学習に不要になるため削除します。
)
print("データセットのトークン化が完了しました。")
# --- 3. PEFT (LoRA) の設定 ---
# LoRA (Low-Rank Adaptation) は、元のモデルの重みをフリーズし、
# 小さなアダプター層を追加して学習させることで、効率的にファインチューニングを行います。
# これにより、GPUメモリの使用量を抑えつつ、高い性能を実現できます。
lora_config = LoraConfig(
r=16, # LoRAのランク。値を大きくすると表現力が増すが、メモリ消費も増える。
lora_alpha=32, # LoRAのスケーリング係数。rの2倍程度が推奨されることが多いです。
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], # LoRAを適用する層。Llamaモデルで一般的な層。
bias="none", # バイアスを学習しない設定。
lora_dropout=0.05, # ドロップアウト率。過学習を防ぐために設定します。
task_type=TaskType.CAUSAL_LM, # タスクタイプを因果言語モデルに設定。
)
# モデルにLoRAアダプターを追加します。
model = get_peft_model(model, lora_config)
print("モデルにLoRAアダプターを適用しました。")
model.print_trainable_parameters() # 学習可能なパラメータ数を確認します。
# --- 4. 学習の実行 ---
# 学習済みモデルを保存するディレクトリ
OUTPUT_DIR = "./llama3_finetuned_model/" # ユーザーが入力したパスがここに挿入されます
# 学習の設定
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
num_train_epochs=3, # エポック数。データセットのサイズと希望する精度に応じて調整してください。
per_device_train_batch_size=1, # GPUあたりのバッチサイズ。VRAMが少ない場合は1に設定。
gradient_accumulation_steps=4, # 勾配を蓄積するステップ数。実質的なバッチサイズは per_device_train_batch_size * gradient_accumulation_steps になります。
optim="paged_adamw_8bit", # 8bit AdamWオプティマイザを使用し、メモリ効率を向上させます。
save_steps=500, # 500ステップごとにモデルを保存します。
logging_steps=100, # 100ステップごとにログを出力します。
learning_rate=2e-4, # 学習率。
fp16=True, # 混合精度学習を有効化 (GPUが対応している場合)。VRAM削減と高速化に寄与します。
max_steps=-1, # num_train_epochsに基づいて学習します。
group_by_length=True, # 同じ長さのシーケンスをグループ化し、パディングを削減します。
lr_scheduler_type="cosine", # 学習率スケジューラーのタイプ。
warmup_ratio=0.03, # ウォームアップ比率。
report_to="none", # レポート先を指定しない (wandbなどを使用しない場合)。
)
# トレーナーの初期化
# data_collatorは、モデルの入力形式に合わせてデータを整形します。
trainer = Trainer(
model=model,
train_dataset=tokenized_dataset["train"],
args=training_args,
data_collator=lambda data: {
'input_ids': torch.stack([f['input_ids'] for f in data]),
'attention_mask': torch.stack([f['attention_mask'] for f in data]),
'labels': torch.stack([f['input_ids'] for f in data]), # 因果言語モデルでは、入力自体がラベルとなります。
},
)
# 学習の開始
print("Fine-tuningを開始します...")
trainer.train()
print("Fine-tuningが完了しました。")
# --- 5. 学習済みモデルの保存 ---
# LoRAアダプターのみを保存します。これにより、ファイルサイズが小さく、効率的に管理できます。
trainer.save_model(OUTPUT_DIR)
print(f"学習済みLoRAアダプターが '{OUTPUT_DIR}' に保存されました。")
# 保存したアダプターを使って推論を行う方法の例 (コメントアウトされています):
# このコードは、ファインチューニング後にモデルをロードして推論を行うための参考例です。
# from peft import PeftModel
#
# # 元のモデルをロード (学習時と同じ量子化設定を使用します)
# base_model = AutoModelForCausalLM.from_pretrained(
# MODEL_NAME,
# quantization_config=bnb_config,
# device_map="auto",
# trust_remote_code=True
# )
#
# # 保存したLoRAアダプターを元のモデルに結合します。
# peft_model = PeftModel.from_pretrained(base_model, OUTPUT_DIR)
#
# # 推論モードに設定します。
# peft_model.eval()
#
# # テキスト生成の例
# prompt = "ローカルPCでのLlama 3ファインチューニングの利点とは"
# inputs = tokenizer(prompt, return_tensors="pt").to("cuda") # 入力をGPUに移動
#
# with torch.no_grad(): # 勾配計算を無効化し、メモリ使用量を削減
# outputs = peft_model.generate(
# **inputs,
# max_new_tokens=200, # 生成する新しいトークンの最大数
# do_sample=True, # サンプリングによる生成を有効化
# top_p=0.9, # Nucleusサンプリングの閾値
# temperature=0.7, # 生成の多様性を制御する温度
# eos_token_id=tokenizer.eos_token_id # 終了トークンID
# )
# print("\n--- 生成されたテキスト ---")
# print(tokenizer.decode(outputs[0], skip_special_tokens=True))明日へ続く
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
```, ;;), )。, アウト, アシスタント, アダプター, あたり, アップ, あなた, いくつ, ウォーム, エポック, エラー, エントリ, オープン, オプティマイザ, お金, クラウドサービス, グループ, クン, ゲーミング, コード, コア, ここ, こと, コミュニティ, コメント, これ, サイズ, サンプリング, サンプル, シーケンス, スクリプト, スケーリング, スケジューラー, スタイル, ステップ, スペック, すべて, ソース, そこら, タイプ, ダウンロード, タスク, ため, チューニング, ツール, データ, データセット, テーマ, ディレクトリ, テキスト, デバイス, デフォルト, トー, トークナイザー, とき, どれ, トレーナー, ドロップ, バイアス, パス, バッチ, パディング, パラメータ, バランス, ファイル, ファイルサイズ, ファインチューニング, ファインチューニングコード, フリーズ, プロ, プロンプト, マシン, マッピング, メモリ, モード, モデル, もの, ユーザー, よう, ライター, ライブラリ, ラベル, ランク, リモート, レベル, レポート, ローカル, ロード, ログ, 一般, 一部, 上記, 不要, 世界, 世界中, 並み, 並列, 予算, 付与, 以下, 以降, 企業, 使い, 使用, 係数, 保存, 個人, 優秀, 入力, 公開, 共有, 具体, 処理, 出力, 分割, 分散, 分野, 初期, 利点, 利用, 制御, 削減, 削除, 創造, 加速, 助け, 効率, 動作, 勾配, 十分, 参考, 反映, 可能, 向上, 味方, 因果, 場合, 多様, 夢物語, 大幅, 大量, 失敗, 学習, 完了, 完全, 完璧, 実現, 実行, 実質, 寄与, 対応, 専門, 導入, 少量, 工夫, 希望, 常識, 強力, 形式, 必要, 思い, 性能, 手元, 手法, 技術, 抜群, 指定, 指示, 挿入, 推奨, 推論, 提供, 整形, 新た, 方法, 日々, 明日, 明確, 明示, 時代, 時間, 最大, 最新, 最適, 有効, 未知数, 本格, 格段, 格納, 構築, 様々, 比率, 民主, 活用, 活発, 消費, 混合, 済み, 温度, 準備, 無効, 無料, 特定, 特権, 現実, 理由, 環境, 生成, 発生, 登場, 的確, 相性, 短時間, 確認, 秘訣, 移動, 程度, 管理, 節約, 精度, 終了, 結合, 結果, 続行, 能力, 自体, 自分, 自動的, 蓄積, 表現, 言語, 計算, 記事, 設定, 許可, 調整, 費用, 軽量, 追加, 通常, 適用, 選択, 重み, 重要, 量子, 開始, 開発, 関数, 閾値, 非常, 高速, 高額, 魅力,
chatGPTでは自然言語で指示が出来る。 #chatGPT
2023.04.11
おはようございます、chatGPTでは自然言語で指示が出来ます。例えば下記のような文言で指示をすると以降、そのルールに対応して回答をChatGPTが行ってくれます。これはChatGPTに限らず日本ではまだ公開(提供)されていないBardでも同じことが出来ます。
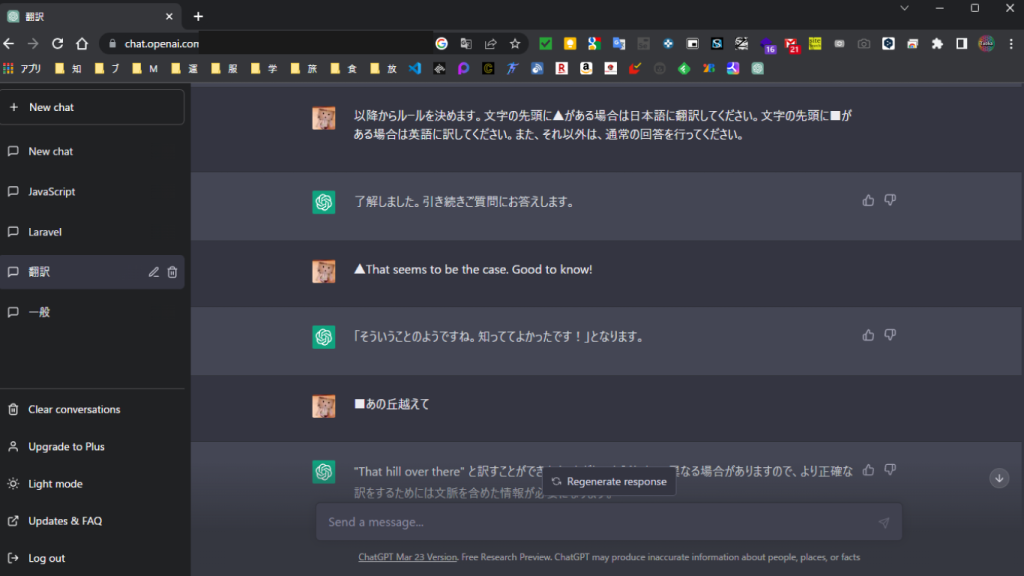
以降からルールを決めます。文字の先頭に▲がある場合は日本語に翻訳してください。文字の先頭に■がある場合は英語に訳してください。また、それ以外は、通常の回答を行ってください。
今回のルールは単純なものでしたが、ルールを複数作ることで複雑な問題も解決してくれるchatGPTになります。尚、基本中の基本ですがNewChatをあまり作らずに分類ごとにまとめ、その分類ではその内容の質問を投げかけることで、より良いchatGPTになります。
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
Bard, ChatGPT, NewChat, ルール, 下記, 先頭, 分類, 分類ごと, 回答, 基本, 指示, 文字, 文言, 良いchatGPT, 英語, 複数, 言語, 質問, 通常,

そういやインフラ系やサーバーサイドのYOUTUBERってあまり知らないよね。
2022.10.26
おはようございます。先日、コロナワクチンを接種して熱が出たので昨日、薬を飲みました。本日は通常と変わらないですという予約投稿を書いている日曜日の夜。
さて、今日はサーバーサイドのYOUTUBERを見かけたのでご紹介です、お名前はうんちゃまさん、何故、そんな名前なのかや動画をまだ三本しか見ていないので、どんな人なのか等は分からない部分は有るものの。そんな悪人さんではないみたいなので、今回、ご紹介します。
サーバーを建てるに当ってどういう所を気にしているのかとか、自分の知見はどの程度なのかの答え合わせが出来て良かったと思っています。
因みにうんちゃまさんは、マイクラサーバーを運営している人です、自分も昔、マイクラサーバーを運営したいなと思って友人にマイクラサーバーは儲かるのか質問した事があります。結果、儲からないとの返答を得たので結局、運営せずに今に至っています。うんちゃまさんは、有志などがいて何とかなっているらしいです。自分もそういうITエンジニアの横のつながりが欲しいなというこの頃。
トイウコトデ、うんちゃまさんのYOUTUBEチャンネルはこちら
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
YOUTUBER, インフラ, うん, コロナ, ご紹介, サーバー, マイクラ, ワクチン, 三本, 予約, 事, 人, 今, 今回, 今日, 儲, 先日, 動画, 友人, 名前, 夜, 悪人, 所, 投稿, 接種, 日曜日, 昔, 昨日, 有志, 本日, 気, 熱, 知見, 程度, 答え, 結果, 自分, 薬, 質問, 返答, 通常, 運営, 部分,

AWAY(アウェイ)、動物視点のゲーム。一見は百聞にしかず!!
2021.09.25
朝は本当に涼しくなってきましたね、何年ぶりだろうか、高知県で秋らしい秋になるのは毎年、秋っていう感覚がなくいきなり冬が来たって感覚がここ数年続いていたように思えます。そして去年よりも今年の冬は寒そうな予感さえします。
さて、AWAY(アウェイ)という変わったゲームを紹介します。このゲーム、動物を操作してそれぞれの視点を体感できるゲームになっています。今までも動物視点のゲームはあったんだけど、2022年に配信される AWAY(アウェイ) が一番リアルかなと思っています。値段も安くてダウンロード専用の通常版だと2,178円と格安です。
唯、こういうゲームはとても素晴らしいだけど、一般的にヒットするかと言えばそうではなく理科好きな少年少女たちにしか受け入れないのかもなと思ってしまいます・・・・。
尚、PS4、PS5に対応していますので、こういうジャンルが好きな方は是非遊んでみてください?。
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
178, 2, 2022, 4, 5, AWAY, PS, アウェイ, ゲーム, ここ, ジャンル, それぞれ, ダウンロード, ヒット, リアル, 一見, 予感, 今年, 体感, 何年, 値段, 冬, 動物, 去年, 唯, 対応, 専用, 少女, 少年, 感覚, 操作, 数, 方, 朝, 本当, 格安, 毎年, 理科, 百聞, 秋, 紹介, 視点, 通常, 配信, 高知県,
精神疾患は公に公表すべきか?するべきではないか?
2016.01.21
先日、統合失調症の記事で新たな発見がありました。これにより研究が進むことを祈っています。
統合失調症は100人にひとりの割合で発症します。100人いればひとりは発症するという割合は結構高いです。
この頃、正しい知識を持った人が増えてきているように思えます。まず、発症後、薬を飲むと70%ぐらいのひとは通常の状態に戻ります。残念ながら30%以下のひとは通常の社会生活を送ることが難しくなります。ただ、今回の発見で今まで通常の状態に戻らなかった人にも光が見えてきたように思えます。
(詳しく内容を読みたい方はこちらより。)
正しい知識と文面で書きましたが統合失調症の場合、発症という言葉や再発の言葉が正しい言い回しではないと自分は感じます。統合失調症の方が急に可笑しな言動に走ることはまず、ありません。何らかのストレスが慢性し被害妄想が増えていき、思い込みが増え、変な行動が増し最終的に幻聴になり社会生活が難しくなるという様に段階があります。(一ヶ月?数ヶ月:段階的に悪くなる=悪くなる兆しは外的ストレスが多い)(※幻覚が現れたりするなどはかなり重くなっている可能性あり)
なお、自分の考えでは精神疾患を公に公表することはしないほうが良いと思います。
何故か?不利益を被ることがあるからです。これは精神疾患に限らず、他の病気でも同じだと感じます。人はそれぞれ考え方が違います。理解力のあるひともいれば、正しくないことを正しいと認識している人もいるからです。よって、公表する場合は、いろいろな人がいる事を認識しそう言った人にも耐えうる人なら公表するべきです。
自分は公表することをオススメはしません。尚、統合失調症というのは統合と書かれている通り、他の疾患もあります。強いストレスにより統合失調症は発症すると言われています。そういう事も有り鬱傾向などが現れたりする場合があります。他にも、統合失調症でかつ発達障害が見られるケースやいろいろなケースがあります。なので、世の中の人達が正しい認識を持つまでは公表するべきことではないと思います。誰も自分の代わりなってくれる人はいないからです。
著者名
@taoka_toshiaki
※この記事は著者が30代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
100, 30, 70, こちら, こと, これ, ストレス, ひと, ひとり, 人, 今回, 先日, 光, 公, 公表, 内容, 再発, 割合, 場合, 変, 失調, 幻聴, 慢性, 文面, 方, 残念, 段階, 状態, 疾患, 発症, 発見, 知識, 研究, 社会生活, 精神, 統合, 自分, 薬, 行動, 被害妄想, 言動, 言葉, 記事, 通常, 頃,