2026.01.14 音楽とリピートリストを作っている. おはようございます.音楽をよく聞く人はメンヘラ傾向が強いとか言われている.自分と音楽の出会いは中学生あたりで、その頃から爆音で音楽を聞いています.それがこの40代になっても変わっていなくて爆音で音楽を流しています. 何故 […]
2026.01.04 明日から仕事:正月休み最終日. おはようございます.明日から仕事:正月休み最終の方も結構いると思います、自分は明日から就職活動の再開になります.そろそろ就職先を決めたいところですが、長く働ける職場環境の会社を探しています. それが自分にとって優先なので […]
2025.12.16 未来予想したかったら米国と中国を見よ. おはようございます.未来予想をする前に米国で起きたことは10年内に日本でも起こる出来事であることです.だいだい都市からそういう技術的なことが取り入れて地方都市、地方と侵食されていく.高知県はそういうのが一番遅いのでだいぶ […]
2025.11.21 テック業界と一般のひとと近づきあるのかな? おはようございます.AI使っている人が増えつつあるとは思うだけど実際どうなんだろう?一般業界の人でAIを使っているひとはどれぐらいいるのだろうかと. AIを使う人が増えてきたらテック業界には結構打撃になる可能性があるなっ […]
2025.11.19 出来たけどレンタルサーバー向きではないと思っているけど おはようございます.先日の続きの話、出来たけどレンタルサーバー向きではないと思っているけど「仕方がない」.仕方がない理由は処理がサクサク動くAWSサーバーを借りれるほど軍資金もないので、レンタルサーバーでほそぼそと動かそ […]
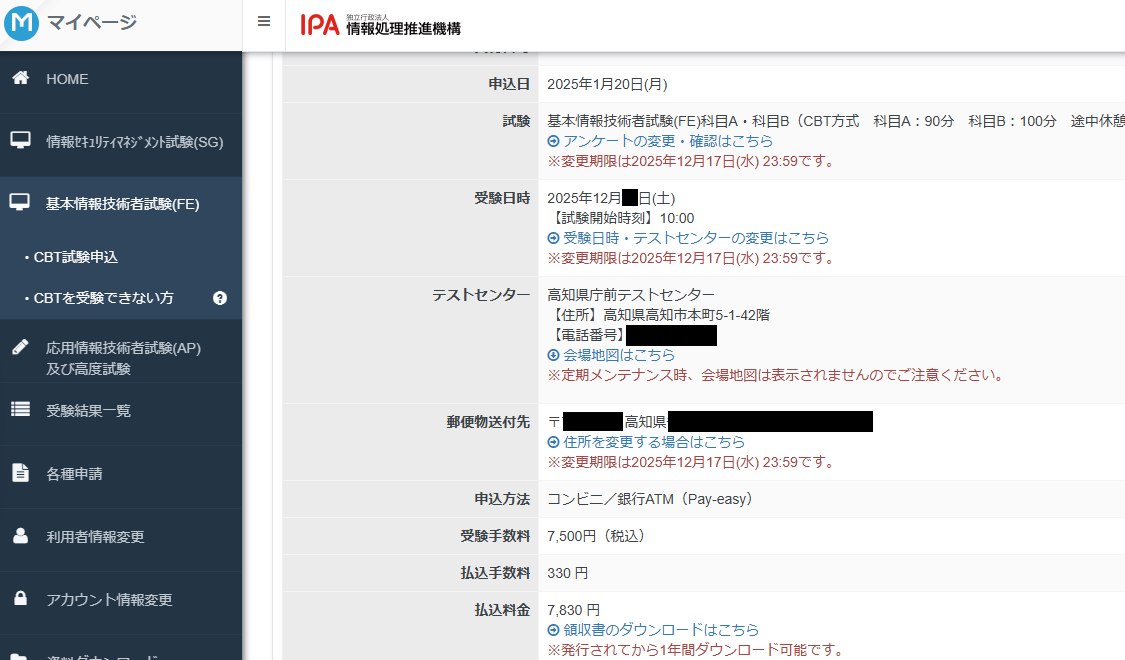
2025.10.10 基本情報技術者の試験日は1年間延長を繰り返すことが出来ます. おはようございます.基本情報技術者の試験日は1年間延長を繰り返すことが出来ます、なのでまだ基本情報技術者を受けに行っていない状態です.今年の暮れあたりに試験を受けに行きます、理由は落ちても受かっても暮れなので良いかなとい […]
2025.09.30 敗者のゲームという本を金高堂で購入 おはようございます.敗者のゲームという本を金高堂で購入して読み進めていますが、これでインデックス投資を始めてみようとか、そういう訳ではなく.本屋さんで立ち読みしていたらなんか読みやすさと共感に惹かれて購入しました. まだ […]
2025.08.25 タグを出現回数によってタグの文字の大きさを変更するコードを実装しました. おはようございます.先日の休みに昼寝から目を覚ましたときに「あっそういや」と思って実装した機能がタグを出現回数によってタグの文字の大きさを変更するコードでした.記事の最後の最後あたりに付いているタグ文字の大きさが記事によ […]
2025.08.15 エイリアン:アースが悩ましい.9月に契約が切れるのだけども. おはようございます.エイリアン:アースが悩ましい.将軍を観るためにディズニープラスを1年間した契約が9月に契約が切れるのだけども、このタイミングでエイリアンアースがリリースされた. 凄く悩ましい. エックスにポストしたけ […]
2025.08.06 宇宙兄弟がもうすぐ完結するだって.宇宙兄弟にはいろいろと人生が詰まっている おはようございます.宇宙兄弟がもうすぐ完結するだって.宇宙兄弟にはいろいろと人生が詰まっています、いまお金がある時に爆買いした宇宙兄弟を読み進めていて12巻の後半まで読み終えました(11巻まで前回読んでいたけどまた読み直 […]
2025.07.15 ワードプレスのテーブルwp_postsデータを取ってきてLaravelで表示. おはようございます.ワードプレスのテーブル(wp_posts)データを取ってきて別サイト(Laravel)にて表示してます.別サイトには広告が付かない感じです.因みにデータは自サイトのブログデータを使用していますが随時去 […]
2025.06.22 AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでも. おはようございます.AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでもなくローカルPCでそこら辺に落ちているLlamaモデルを持ってきてチューニングすれば何とかなるじゃねぇという思いに至った. […]
2025.06.14 映画、フロントラインを観てきました、ネタバレ無しの感想 おはようございます、映画、フロントラインを観てきました、ネタバレ無しの感想を書いていきます.これは胸熱な物語でした観てよかったです、観たいなって思っている方は是非劇場に足を運んでください熱い思いがお釣りとして返ってきます […]
2025.01.03 ネトフリで映画65 シックスティ・ファイブを中盤まで観てラストまで飛ばし観した話. おはようございます.ネトフリで映画65 シックスティ・ファイブを中盤まで観てラストまで飛ばし観した話を書いています.まずこの映画、大スクリーンかVRで観ないと楽しめない作りになっています. ストーリー的には地球が舞台にな […]
2021.11.17 JavaScript(js)でcsvファイルを読み込み自動計算する(合計sum) 謎の訪問者さんが検索窓を使用して何度かググっているので要望にお応えJavaScript(js)でcsvファイルを読み込み自動計算する(合計sum)というものを作りました。以前、csvを元にテーブルを作成するものを作ってい […]
2020.07.24 長年、デスクワークしていると。(あるあるネタ) 長年のデスクワークをしていると、お腰をかなりの確率で痛めます、じぶんはいま、椅子に座ると痛みに耐えながら、プログラミングなどをしています。 たぶんかなり重症なケースだと思います。痛み止めがほしいぐらい、背骨からお腰のあた […]
2020.04.09 ローソンから発売されたグーボを食べてみた。 ローソンから発売されたグーボを食べてみた。今回食べたのは明太子チーズ味とメキシカンチョリソー味です。今回は買いませんでしたがベーコンポテト味があります。 さて、お味の方は外はサクサクで、中の具はジューシーさがあります。今 […]
2020.03.15 inliving=いん りびんぐと読みます。 いんりびんぐ(ririka / vlog)さんのvlogです。中堅YOUTUBERというあたりのポジションかなと思います。ちなみに自分が知った頃はもっと登録者数は少なかったように覚えています。このひと、数年前からYOUT […]
2018.11.23 いろいろエディタやIDEを試してみてこれが良いかなと。 IDEとエディタの境目あたりで言えばATOMかVisual Studio Codeですね。 IDEでPHPを使用するならばNetBeansかなと思います。 ATOMに関してはいろいろ試してみてこれだけのプラグインをインス […]
2016.06.14 本:お金の教養を読んでみた。 お金の教養を読んでみた。 pic.twitter.com/MdpjiZjg7S— 田岡 寿章@taoka_toshiaki🦌 (@taoka_toshiaki) June 13, 2016 お金に無頓着な自分 […]
2014.11.09 映画を観に行くつもりでしたが結局・・・{サボタージュ}。 映画を観に行くつもりでしたが、今日は結局、観に行きませんでした。昨日、サボタージュという映画を観に行ったのですが・・・。あまりにもグロかったので途中退席しました。自分が映画で途中退席するのは・・・・もしかするとはじめてか […]
2014.08.27 思考をやわらかくする授業読んでみて(`・ω・´) 思考をやわらかくする授業を読んでみて{パラ読み}、少し感想を書いてみますね。第一印象は読みやすいです。最初は本に引き込ますためなのか、挿絵(写真)とデカ文字が多かったです30ページを超えたあたりから普通の本ぐらいの活字の […]
2014.08.17 土佐人{自作サイト}、鳴かず飛ばず!?。 土佐人{tosajin.info}という自動更新サイトをひとつ制作しているのですけど、本当はもっと、まともなポータルなサイトにしたいですね。でも、金ナシ、やる気なしな自分がいます。本当はもっとやりたいことはあるんです。ア […]