2025.11.18 VPSを解約してその処理をレンタルサーバーで行いたいですよね~ おはようございます.今日から寒くなるそうです、これを書いている時はぽかぽか陽気の日曜日のお昼に書いています. さて「VPSを解約してその処理をレンタルサーバーで行いたいですよね~」という事ですがもしかしたら動かせる可能性 […]
2025.11.09 観ずになりそうな映画、その壱その弐 おはようございます.先日は久しぶりに温かな陽気でしたね、今日(2025-11-07)もそんな陽気になりそうです.さて、これを書いているのは金曜日です、いつもなら映画を午前中に観に行っているものですけど、映画を観ずにウォー […]
2025.10.21 自宅サーバーにしようかなと検討している.その方法は おはようございます.この頃、経費削減のため必要ないだろうというサブスクの解約を進めています.例えばラジコは解約、ディズニープラスも解約、メールサーバも解約、レンタルサーバーライトも解約とまぁ年間で一万5千円ぐらいの解約を […]
2025.09.29 ブログは必要最低限の広告にしました. おはようございます.ユニクロさんが秋冬用を変わっていたけど大丈夫かなって思っていたけど、今日はエアコン無しで仕事が出来るような季節になってきましたね.さて、コアなユーザー(読者)さんならお気づきかも知れませんが、広告をか […]
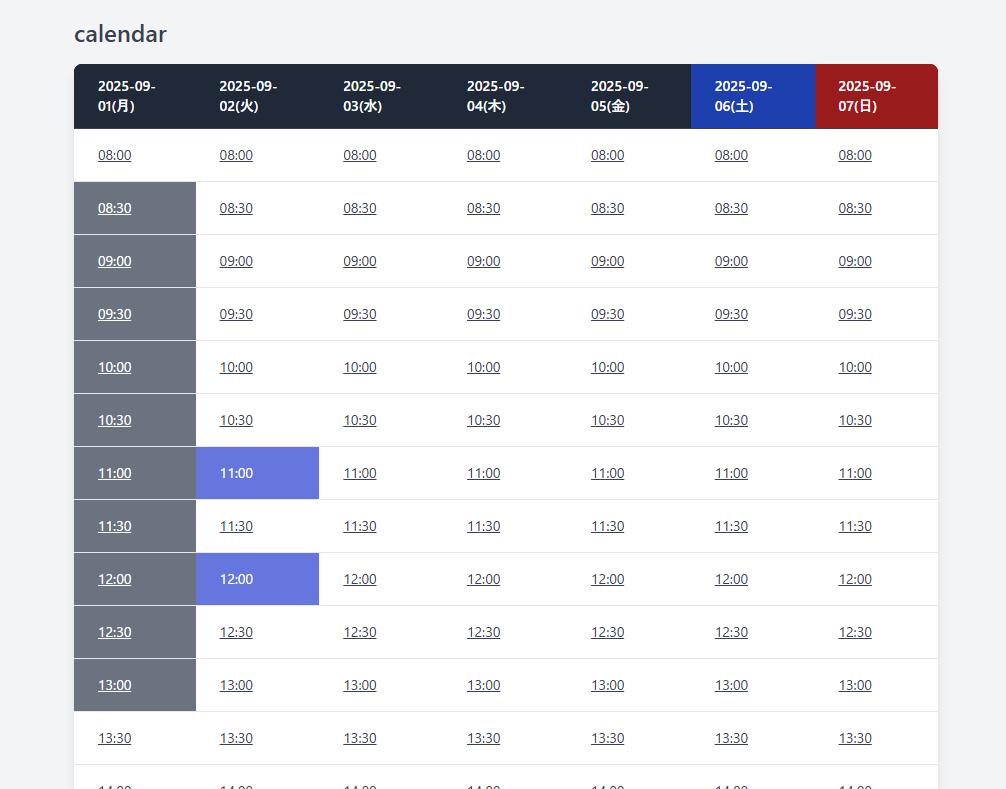
2025.09.14 予約システム(仮)を作った話をRECしてとか おはようございます.予約システム(仮)を作った話をYOUTUBE用にRECしてとかコードを昨日のお昼まで大体作ってました.結局、エンジニアさんが欲している部分は事足りると思っています. あとはエンジニアさんがカスタマイズ […]
2025.07.13 チャットワークのAPIを使ってみました.プロンプトでほぼ書いています. おはようございます.チャットワークのAPIを使ってみました.プロンプトでほぼ書いたコードになります、チャットGPTの無料版にリファレンスのURLリンクとPHPのクラス化、リターンに$thisで返却出来る所は$thisを使 […]
2025.07.05 AI時代のマーケティング激変に備えよグーグル検索の60%がクリックされない おはようございます.先日、自分が言っていた事は間違いなかったんだなって下記の動画を見て思いました.これから先、SNSとAIを駆使しないと集客出来ない時代になるということですね.要するに検索というものは廃れていくということ […]
2025.06.22 AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでも. おはようございます.AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでもなくローカルPCでそこら辺に落ちているLlamaモデルを持ってきてチューニングすれば何とかなるじゃねぇという思いに至った. […]
2022.06.28 AWSからVPSへ鞍替えするつもりでいますが😌 おはようございます。6月ももうすぐ終わりますね。 AWSからVPSへ鞍替えするつもりでいます。今すぐに鞍替えするつもりはないのですが数カ月後には鞍替えするつもりでいます。もしくはAWSのライトセイルに戻すかもしれません。 […]
2022.01.08 お気づきかと思いますが、サーバーを密かに変えました。(密かではないですけど。) お気づきかと思いますが、サーバーを密かに変えました。変えたのは年末あたりです、それから裏と表でサーバーをゴニョゴニョして何とか運用している感じです。変えた理由は経費削減ということが一番の理由ですね😌。 変えたことにより表 […]
2019.12.29 jaxaの初任給が破格のお値段 jaxaの初任給が破格のお値段です? 昨日、こんなつぶやきをしたのですが…本当にJAXAのお給料は破格の値段ですね。。。 これでも求人に殺到するだから、お金では無いと思います。ちなみにJAXAの初任給は19万円です、30 […]