story of my life
過去の蓄積を見るために書く日記.

AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでも.
2025.06.22
おはようございます.AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでもなくローカルPCでそこら辺に落ちているLlamaモデルを持ってきてチューニングすれば何とかなるじゃねぇという思いに至った. […]
 著者名
@taoka_toshiaki
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
```, ;;), )。, アウト, アシスタント, アダプター, あたり, アップ, あなた, いくつ, ウォーム, エポック, エラー, エントリ, オープン, オプティマイザ, お金, クラウドサービス, グループ, クン, ゲーミング, コード, コア, ここ, こと, コミュニティ, コメント, これ, サイズ, サンプリング, サンプル, シーケンス, スクリプト, スケーリング, スケジューラー, スタイル, ステップ, スペック, すべて, ソース, そこら, タイプ, ダウンロード, タスク, ため, チューニング, ツール, データ, データセット, テーマ, ディレクトリ, テキスト, デバイス, デフォルト, トー, トークナイザー, とき, どれ, トレーナー, ドロップ, バイアス, パス, バッチ, パディング, パラメータ, バランス, ファイル, ファイルサイズ, ファインチューニング, ファインチューニングコード, フリーズ, プロ, プロンプト, マシン, マッピング, メモリ, モード, モデル, もの, ユーザー, よう, ライター, ライブラリ, ラベル, ランク, リモート, レベル, レポート, ローカル, ロード, ログ, 一般, 一部, 上記, 不要, 世界, 世界中, 並み, 並列, 予算, 付与, 以下, 以降, 企業, 使い, 使用, 係数, 保存, 個人, 優秀, 入力, 公開, 共有, 具体, 処理, 出力, 分割, 分散, 分野, 初期, 利点, 利用, 制御, 削減, 削除, 創造, 加速, 助け, 効率, 動作, 勾配, 十分, 参考, 反映, 可能, 向上, 味方, 因果, 場合, 多様, 夢物語, 大幅, 大量, 失敗, 学習, 完了, 完全, 完璧, 実現, 実行, 実質, 寄与, 対応, 専門, 導入, 少量, 工夫, 希望, 常識, 強力, 形式, 必要, 思い, 性能, 手元, 手法, 技術, 抜群, 指定, 指示, 挿入, 推奨, 推論, 提供, 整形, 新た, 方法, 日々, 明日, 明確, 明示, 時代, 時間, 最大, 最新, 最適, 有効, 未知数, 本格, 格段, 格納, 構築, 様々, 比率, 民主, 活用, 活発, 消費, 混合, 済み, 温度, 準備, 無効, 無料, 特定, 特権, 現実, 理由, 環境, 生成, 発生, 登場, 的確, 相性, 短時間, 確認, 秘訣, 移動, 程度, 管理, 節約, 精度, 終了, 結合, 結果, 続行, 能力, 自体, 自分, 自動的, 蓄積, 表現, 言語, 計算, 記事, 設定, 許可, 調整, 費用, 軽量, 追加, 通常, 適用, 選択, 重み, 重要, 量子, 開始, 開発, 関数, 閾値, 非常, 高速, 高額, 魅力,

北斎展 師とその弟子たちを見てきましたよ。in 高知県立美術館
2022.07.23
おはようございます。昨日、北斎展 師とその弟子たちを高知県立美術館で見てきました。 葛飾北斎は繊細と躍動感を兼ね備えた絵だということ、センスは半端ないな。一つ惜しい所は絵の為に照明を落としていたことです。照明を落とすのは […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
1, 200, in, オレンジ, お得感, こと, センス, そこ, 一つ, 事, 京都, 今度, 伊藤若冲, 写真, 北斎, 半端, 反映, 多数, 少し, 展, 弟子, 感じ, 所, 昨日, 本物, 東京, 残念, 為, 照明, 県立, 絵, 繊細, 美術館, 色, 色合い, 葛飾北斎, 躍動感, 高知,

2023年7月からGA4に変わるだってさ。桐島くん。
2022.07.20
おはようございます。下記の記事には桐島くんは関係ありません😌。 2023年7月からGA4に変わるそうです、一年前から告知している、Gさん。自分は2022年の7月から変わるだと思い込んでAnalyticsの対応を全て行いま […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
-GA, 2022, 2023, 3, 4, 7, Analytics, web, アクセス, あれ, カウント, コード, こと, これ, ソース, ところ, ユーザー, リアルタイム, リリース, 一, 下記, 今, 仕方, 仕様, 全て, 反映, 吐息, 告知, 変更, 対応, 廃止, 数え方, 桐島, 業界, 無料, 移行, 翌日, 自分, 解析, 記事, 訪問者, 関係, 頃,
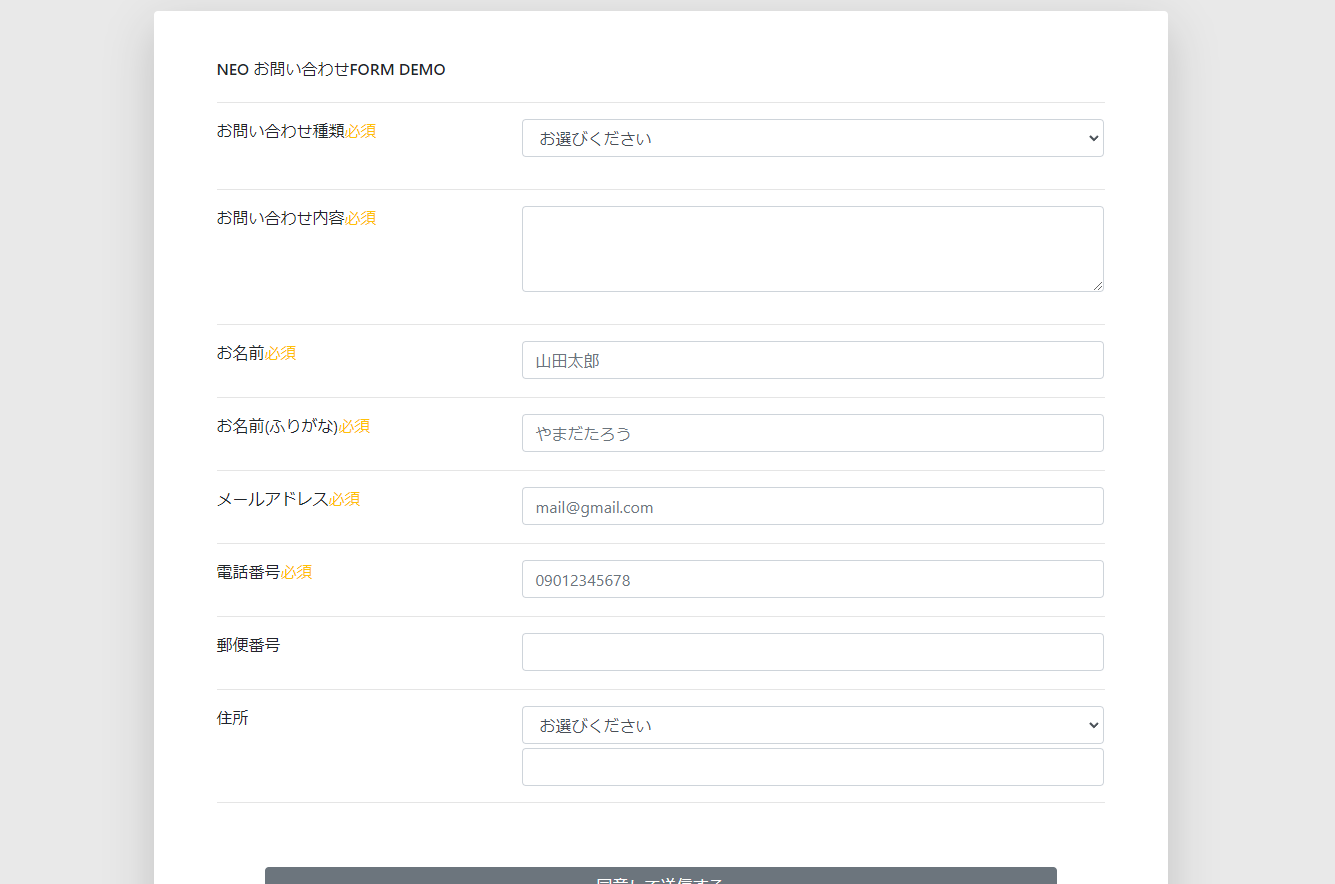
T2のお問い合わせフォームフロント側が緩く完成、続きは今の所なしかな。
2021.10.26
朝起きは三文の徳ですが・・・。本当なのでしょうか、朝方からお問い合わせフォームのちょこちょこと残りを制作しておりました。 T2のお問い合わせフォームフロント側が緩く完成しました、パチパチ?。この雛形を元に制作してください […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
2, am-BShXaVuI, com, github, https, push, watch, www, youtube, お問い合わせ, コード, ソース, フォーム, フロント, ページ, 三, 事象, 今, 何度, 作り, 使用, 元, 制作, 労力, 即興, 反映, 反省, 完成, 得意, 徳, 所, 時間, 朝方, 朝起き, 本当, 業者, 汎用性, 結構, 訳, 部分, 雛形, 頃,
半生生きたのか分からない。
2020.10.18
常識的に言えばいま自分は半生ぐらいの年月を生きたのかもしれないけれど、これから数十年生きていれば、医学も発展し不老不死まではいかないまでも、健康な状態で長生きできる期間が増えるのではないかと思っています。あの完全自動運転 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
IT, いま, これ, コロナ, シフト, すべて, それ, ひと, まま, もっとも, リモート, ワーカー, わけ, 不老不死, 世, 中, 予測, 人, 人々, 企業, 健康, 全体, 医学, 半生, 反感, 反映, 完全, 年月, 数十, 方, 日本, 期間, 未来, 業界, 権力, 横, 状態, 生活, 発展, 研究, 終息, 結果, 考え方, 自分, 自動, 話, 運転, 長生き, 頂点,
テクノロジー見るだけノートを読み終えた。
2020.01.27
テクノロジー見るだけノートを読み終えたので感想を残しときます。最新テクノロジー好きなひとはこの本に書かれていることの大半は知っている気がします。ひとつ自分が知らなかった事が書かれていたサイボーグレンズ、これ眼球をサイボー […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
ar, beyondMeet, Mr, あと, お肉, グーグル, こと, これ, サイボーグ, そこ, それ, テクノロジー, ところ, ノード, ひと, ひとつ, ビヨンド, ミート, レンズ, 事, 人, 会社, 作物, 内容, 分野, 反映, 味, 大半, 学年, 小学, 感想, 最後, 最新, 本, 機関, 正直, 殺生, 気, 牛, 理解, 発展, 眼球, 研究, 自分, 解説, 遺伝子組み換え, 野菜, 魚, 鳥,
GCPでメール代行するならmailgunだと思います。
2018.01.28
GCPでメール代行するならmailgunだと思います。 GCPではポート番号、25とか110とかメール系のポートはセキュリティ上の 関係ですべてシャットアウトしています。 25番ポートなんてずっと閉じている。 メール中継 […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
GCP, Google Cloud Platform入門, Gさん, mailgun, MX, Postfix, お利口さん, お好み, クラウド, セキュリティ上, プログラマ, ポート, ポート番号, メール, メール中継, 但しDNS, 全体像, 反映,