story of my life
過去の蓄積を見るために書く日記.

デコボコな能力を持っている気がします.
2026.01.13
おはようございます.ある領域は他の人より秀でているかもしれないけど、その他のコミュニケーションスキルは人よりも劣っている気がします.特に自分を表現する力に関しては劣っていると自分は思っています. この話は先日の緊張と滑舌 […]
 著者名
@taoka_toshiaki
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
いろいろ, コード, こと, コミュニケーション, これ, スイッチ, スキル, セールス, そう, その他, それ, ダメダメ, テキスト, でこ, ところ, プロ, ボコボコ, もの, よう, 一番, 人達, 以外, 先日, 克服, 創作, 単語, 可能, 営業, 延長線, 必要, 感じ, 改善, 文章, 明日, 欠落, 治療, 真っ白, 瞬時, 結局, 緊張, 能力, 自信, 自分, 自尊心, 表現, 言葉, 過度, 部分, 面接, 領域, 飛び込み,
モールス信号変換器を作った話.二番煎じ感
2025.12.22
おはようございます.競合他社とまでは行かないもののモールス信号変換器を作りました、この機能が検索にヒットするまでには少し時間がかかると思います.AI時代にSEOは必要ないなどと言いますが、実際は必要不可欠なんじゃないかな […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, SEO, SNS, いまいち, こと, サイト, そう, そこ, それ, だし, ネット, パターン, ヒット, ひと, ボット, マーケ, マーケティング, みたい, モールス, もの, ランダム, リンク, 一定, 上位, 不可欠, 人達, 他社, 使用, 信号, 効果, 和文, 変換, 変更, 宣伝, 必要, 方法, 明日, 時代, 時間, 最後, 検索, 機能, 活動, 現状, 発信, 競合, 結果, 締め, 自分, 複数, 重要,

さくらレンタルサーバーデータベースをフルバックアップするコード
2025.12.20
おはようございます.アバターは月曜日か火曜日に観に行くつもりでいますがどうなるかは未定です.本日はさくらレンタルサーバーデータベースをごっそり定期的にフルバックアップするコードを作成したのでその話を書いていきます.このコ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
www, アップ, あと, アバター, エラー, クロン, コード, コマンド, コメント, これ, これら, ころ, さくら, そこ, つもり, ところ, パスワード, バックアップ, フルバック, ユーザー, よう, ライン, レンタルサーバーデータベース, 不要, 作成, 使用, 出力, 削除, 可変, 国家, 場合, 変更, 定期, 実行, 必要, 明日, 月曜日, 未定, 本日, 注意, 火曜日, 環境, 県庁, 結果, 結構, 自由, 自身, 設定, 試験, 辺り, 追伸, 重要, 高知,

アクセスカウンターはSQLiteとPHP言語で出来ています.
2025.12.19
おはようございます、このサイトのアクセスカウンターはSQLiteとPHP言語で出来ています.ボット訪問者はカウントしないなどは別のプログラムで制御しています.そういう訳もあって結構シンプルなコードで出来上がっていると思い […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
IP, MaxMind, php, Sqlite, アカウント, アクセス, アナリティクス, カウンター, カウント, コード, こと, これ, サーバー, サイト, しょう, シンガポール, シンプル, そこ, それ, ダウンロード, データベース, プログラム, ボット, よう, ライブラリ, 一番, 中国, 何処, 使用, 判別, 判定, 制御, 可能, 必要, 方法, 明日, 海外, 登録, 簡単, 経由, 自分, 規約, 解析, 言語, 訪問, 負荷, 遮断, 非常,

AI技術のRAG (Retrieval-Augmented Generation: 検索拡張生成)
2025.12.03
おはようございます.AI技術のRAG (Retrieval-Augmented Generation: 検索拡張生成)をこのブログに取り入れることは可能かも知れないなと思っています.出来たら面白いかも知れないけど、ちょっ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, ChatGPT, Dify, GENERATION, ID, Python, RAG, RetrievalAugmented, VPS, あと, あれ, おすすめ, コード, ここら, こと, これら, コンテキスト, サーバー, スペック, そう, それ, タグ, ディファイ, ノー, プレス, ブログ, マシン, モデル, もの, よう, ラク, レコメンド, レコメンドアルゴリズム, ワールド, 予測, 使用, 傾向, 出現, 前提, 可能, 学習, 完璧, 導入, 必要, 感じ, 技術, 拡張, 数値, 明日, 時代, 時間, 最高, 条件, 検索, 機械, 物理, 環境, 生成, 自分, 記事,

結局買わなかった山善の4K43インチのディスプレイ
2025.12.02
おはようございます.結局買わなかった山善の4K43インチのディスプレイですがブラックフライデーで2万5千円で売られていました.かなりコスパが良いかなと思ったわけですが結局、いまは買わないほうが得策だろうと思って買いません […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, Excel, Mac, MacBook, MacMini, mini, Pro, WindowsPC, いま, インチ, お金, コード, コス, こと, サーバー, ため, ディスプレイ, テック, フライデー, ブラック, プログラム, ほう, もの, ローカル, わけ, 今回, 会社, 使用, 全て, 動き, 好き, 山善, 影響, 得策, 必要, 感じ, 明日, 業界, 段階, 液晶, 現場, 理由, 界隈, 登場, 結局, 自分, 転職, 運用, 選択,

laravelとReactとviteの話です.ローカルサーバーを建てず
2025.11.29
おはようございます.laravelとReactとviteの話です.ローカルサーバーを建てずに直本番にアップロードしてテストしたいなど、こんな場面はあまりないとは思いますが出先でひ弱なPC環境だった場合.Dockerなどを […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
docker, Laravel, nodejs, npm, PC, react, vite, アップ, インストール, ウェア, グローバル, ここ, こと, これ, サーバー, サービス, システム, ディレクトリ, テスト, ノード, パソコン, パッケージ, パブリック, ビルド, ひ弱, ファイル, まる, モジュール, よう, リスク, ローカル, ロード, 一致, 伝染, 停止, 出先, 前提, 問題, 場合, 場面, 対応, 必要, 意味, 慎重, 手順, 方法, 明日, 本番, 条件, 環境, 確認, 自分, 運用,
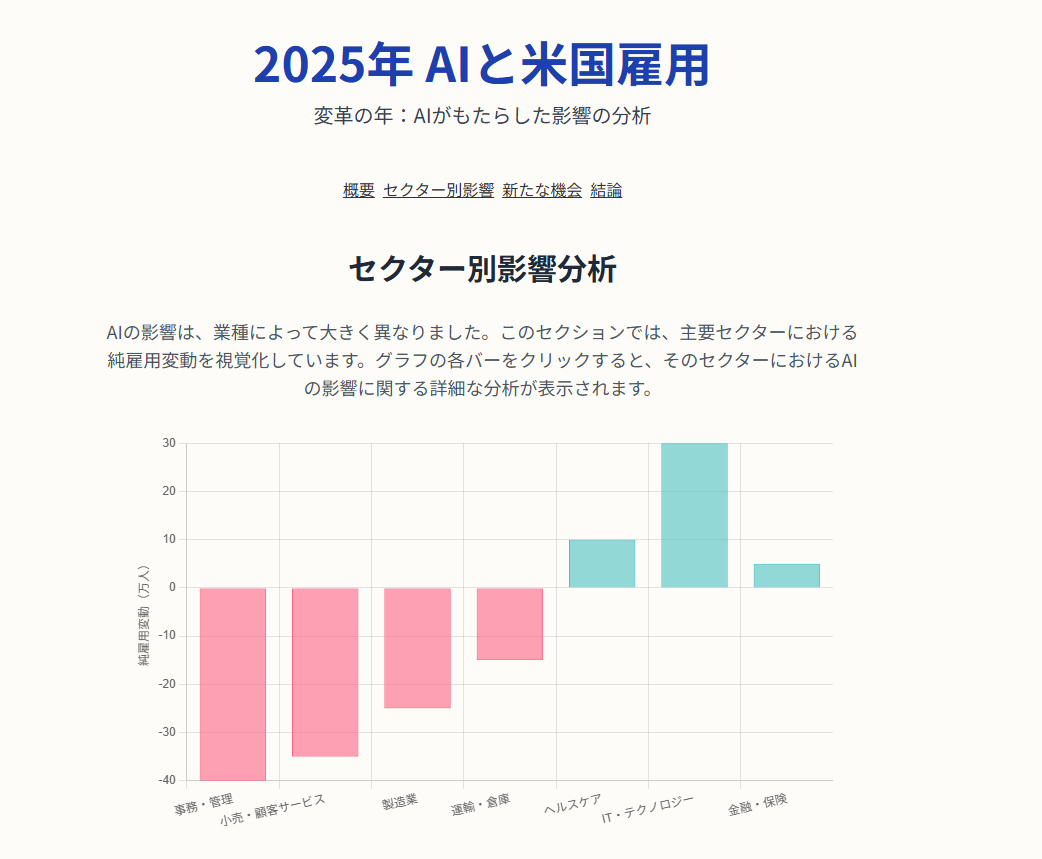
2025年AIと米国雇用をジェミナイに調査して貰って分かった事.
2025.11.25
おはようございます.2025年AIと米国雇用の関係をジェミナイに調査して貰って分かった事は今まで悩んでいたITテック系の雇用のことだけどAIに近しい技術では雇用が増えているみたいです.なので、多少心配は薄れた感じになりま […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, IT, コード, こと, ジェミナイ, シフト, テック, ホームページ, ホワイトカラー, みたい, もの, リスキリング, リストラ, ロボット, 一番, 事務, 今後, 仕事, 動向, 動的, 可能, 定年, 対象, 将来, 影響, 心配, 必要, 意味, 感じ, 技術, 日本, 明日, 最後, 最近, 殆ど, 社会, 米国, 自分, 自動, 複雑, 調査, 関係, 雇用, 高度,

求職者マイページホーム(ハローワーク)のバーコードは何の種類を使用しているの?
2025.11.08
おはようございます.求職者マイページホーム(ハローワーク)のバーコードは何の種類を使用しているの?とAIに投げかけてもぜんぜん違うものをあたかもそうであるように回答してくれるので、AIにお願いしてまずはPython言語を […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, codabar, https, NW, pdf, Python, QR, react, taokatoshiakicomhellowork, お願い, カード, コード, こちら, こと, これ, サービス, サイズ, スマホ, そう, ため, バーコード, ハイフン, ハローワーク, ハローワークカード, ページ, ペラガミ, マイ, マイページホーム, まごまご, みたい, もの, やる気, よう, ライブラリ, リアクト, リンク, 下記, 不便, 今頃, 代わり, 使用, 個人, 出力, 印字, 可能, 回答, 場合, 実行, 対応, 就職, 必要, 把握, 持ち運び, 支給, 明日, 本題, 機械, 求職, 活動, 状態, 現れ, 田舎, 番号, 種類, 窓口, 自分, 言語, 記入, 記載, 識別, 財布, 開発, 面倒,

みんな働いているから偉いなとかお金の話とか人生とか馬鹿みたいに考えた
2025.11.07
おはようございます.今月から無職になり就職活動を行っているのですが、いまの所、さっぱりです.さて、そんな中、ダイエットの一環でウォーキングを小一時間ほど行っている時にタイトルの事を考えて先日歩いていました. 馬鹿みたいな […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
いま, インフラ, ウォーキング, お金, こと, これ, それ, それぞれ, ダイエット, タイトル, ため, チャージ, とき, ところ, どれ, みたい, みんな, もの, リセット, わけ, 一環, 一番, 人生, 人達, 今月, 仕事, 他者, 以外, 価値, 先日, 周り, 場合, 夢物語, 大事, 大変, 奴隷, 家族, 就職, 後悔, 必要, 思想, 意味, 感性, 支障, 放棄, 日々, 日本, 明日, 時間, 期間, 正直, 毎月, 気持ち, 水準, 治安, 活動, 満足, 無職, 現代, 理由, 生き方, 生活, 疑問, 発展, 発明, 社会, 結局, 維持, 自分, 言葉, 豊か, 適切, 重点, 金持ち, 馬鹿,

AIに仕事奪われたって記事はGeminiの生成文、いや分からないって.
2025.11.05
おはようございます.AIに仕事奪われたって記事はGeminiの生成文、いや分からないって思いました.もう文章は人かAIか遜色ないところまで来ているのだなって. 「AIに仕事奪われた」の内容みたいな事になっていて困っている […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, gemini, web, コーディング, サイト, サン, それ, デザイン, とき, ところ, プロ, プロンプト, みたい, 一流, 今後, 仕事, 以外, 修正, 内容, 写真, 問題, 地方, 大体, 好み, 必要, 成文, 担当, 指示, 文章, 文言, 方針, 明日, 時代, 時間, 構図, 構築, 正直, 現状, 申し訳, 画像, 社長, 記事, 貴方, 進化, 遜色, 間違い, 非常,

自宅サーバーにしようかなと検討している.その方法は
2025.10.21
おはようございます.この頃、経費削減のため必要ないだろうというサブスクの解約を進めています.例えばラジコは解約、ディズニープラスも解約、メールサーバも解約、レンタルサーバーライトも解約とまぁ年間で一万5千円ぐらいの解約を […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
cloudflare, https, Trust, Tunnel, VPS, yumenomecloudflaretunnel, ZERO, あと, いま, イラストレーター, お金, こと, これ, サーバ, サーバー, サブスク, システム, シフト, セキュリティ, ソース, そちら, ため, ディズニー, ところ, ニート, プラス, フリー, みたい, みんな, メール, ラジコ, レンタル, レンタルサーバーライト, 予定, 余裕, 再来月, 削減, 合計, 国民, 安全, 年金, 年間, 延期, 徴収, 必要, 担保, 採用, 支払い, 明日, 検討, 正直, 毎月, 発生, 移行, 簡単, 経費, 自分, 自宅, 解約, 記事, 財源, 資産, 面倒,

夢がある.数年前はネットには夢があった、では今は?
2025.10.07
おはようございます.夢がある数年前はネットには夢があった、では今は?今でもネットには夢があると思う、昔よりも夢があるとくにIT技術者は一人や少人数でも開発が出来るようになったと思っています. お金があれば全自動で24時間 […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, Claude, github, IT, アイディア, アンド, いま, エージェント, エラー, お金, コーン, こと, これ, システム, それ, それなり, チャンス, トライ, ネット, もの, ユニ, よう, 人工, 人数, 代わり, 企業, 優秀, 出力, 初期, 判断, 労働, 味方, 問題, 回答, 場合, 導入, 役割, 必要, 技術, 指示, 明らか, 明日, 時代, 時間, 期待, 構築, 次第, 無料, 生成, 生産, 登場, 相棒, 知能, 知識, 答え, 結果, 自分, 自動, 複数, 開発, 雇用,

15年ぐらいのパソコンで生成AIは果たして動くのか?
2025.10.06
おはようございます.15年ぐらいのパソコンで生成AIは果たして動くのか?試してみた結果、ギリ動くという事が分かったのだけど、全く持って使えないという事も判明しました.プロンプトを投げて、最初の一文字が返ってくるのに3分か […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, CUDA, SNS, Windows, キリ, コード, これ, ソース, その他, その後, パソコン, プロンプト, ポスト, モデル, もの, よう, レスポンス, ローカル, 一文字, 事前, 仕事, 仕組み, 休み, 使い物, 使用, 先日, 全て, 全文, 判明, 前回, 動作, 反面, 可能, 場合, 如何, 完了, 必要, 文字, 明日, 最初, 段階, 現行, 環境, 生成, 紹介, 結果, 自分, 表示, 要約, 記事, 記載, 負荷, 通り,

敗者のゲームという本を金高堂で購入
2025.09.30
おはようございます.敗者のゲームという本を金高堂で購入して読み進めていますが、これでインデックス投資を始めてみようとか、そういう訳ではなく.本屋さんで立ち読みしていたらなんか読みやすさと共感に惹かれて購入しました. まだ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, あたり, いつ, インデックス, エリア, ゲーム, ここ, コチラ, こと, これ, サン, スパン, それ, ため, チャールズ, データ, ディトレード, とき, どちら, プレ, プロ, 上記, 人工, 今日, 信託, 債券, 共感, 内容, 冒頭, 分散, 初版, 割合, 勝者, 基本, 大事, 実行, 将来, 市場, 必要, 思い, 感想, 成果, 投資, 敗者, 方針, 明日, 時代, 本屋, 株式, 比率, 登場, 目標, 知能, 程度, 積み立て, 立ち読み, 素人, 経験, 自分, 行い, 言葉, 計画, 読了, 資金, 購入, 通用, 遂行, 達成, 配分, 金高, 長期,

マーケティングは殆ど外れると思ったら良さそうと思った一流でさえ.
2025.09.19
おはようございます.マーケティングは殆ど外れると思ったら良さそうと思った一流でさえいろいろと試行錯誤してやっと当たるだからね. 一流のマーケティング会社さんのマーケティングを知りたい、そんな中で見つけたのがこちらのYOU […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
ウラ, カット, キット, ギリアウト, こちら, こと, ゴミ箱, これ, サン, そう, そこ, ブログ, マーケティング, よう, 一流, 会場, 会社, 動画, 参考, 口コミ, 大事, 大学, 必要, 戦略, 明日, 殆ど, 現場, 自分, 記載, 試行, 試験, 錯誤,

LLMO対策の前手順として、マークダウン記法を施しました.
2025.09.02
おはようございます.LLMO対策の前手順として、マークダウン記法を施しました.シングルページにマークダウン記法のリンクがそれぞれの記事にあると思います. そのリンクをクリックするとマークダウン記法が表示されます.LLMO […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
```, いん, インライン, エラー, お裾分け, クリック, これ, サン, シングル, スクリプト, そちら, それぞれ, ダウン, チェック, チャッピー, とき, パラメーター, ハンドラ, ファイル, フォールバック, フラグ, ページ, ボタン, マーク, ユーザー, よう, リンク, ルート, レスポンス, ログイン, 一行, 下記, 不明, 予定, 先頭, 公開, 処理, 出力, 判定, 削除, 同一, 呼び出し, 場合, 外部, 失敗, 存在, 実行, 対応, 対策, 導入, 当該, 形式, 必要, 手順, 投稿, 新規, 既存, 日付, 明日, 書き込み, 有効, 権限, 状態, 用意, 画面, 発行, 監視, 管理, 自身, 表示, 記事, 記法, 記載, 設置, 認識, 近日, 追伸, 追加, 追記, 遷移, 降順, 非同期,

学生さんが成りたい職業一位は公務員、現実思考.
2025.08.23
おはようございます.学生さんが成りたい職業一位は公務員、現実的だと思いました.. これから先、公務員や会社員になることすら非常に難しくなるだろうなと自分も思っています.そのうち中国人の若者たちのように就職できなかった若者 […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
いま, こと, ころ, コンビニ, サン, それ, タチ, どれ, よう, ロボット, 中国人, 中学生, 人口, 人工, 会社, 光景, 公務員, 公園, 問題, 塩梅, 大人, 学生, 小学生, 就職, 工場, 必要, 悲観, 日本, 明日, 活躍, 浸透, 深刻, 減少, 現実, 知能, 社会, 職業, 自分, 若者, 雇用, 非常,

参考書を買わなくてもドキュメントとAIチャットで学べるようになってきてる.
2025.08.21
おはようございます.この頃、参考書を買おうか悩んだのですが、よくよく考えると参考書を買わなくても公式サイトのドキュメントを読めばなんとかなります.そしてこの頃グーグルの翻訳機能が昔より精度が上がっていて良く使用されるドキ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
アップ, グーグル, コピー, サーバー, サイト, シフト, ショット, スクリーン, ドキュメント, どちら, ビルド, プログラミング, よう, レンタル, ロード, 一部, 上記, 使用, 公式, 内容, 処理, 参考, 必要, 明日, 昨日, 構成, 機能, 熟知, 画面, 精度, 続き, 翻訳, 違和感, 部分,

除外にしているのにノートンのVPNが強力すぎてAmazonやNetflixが見えない時の対処法
2025.08.16
おはようございます.除外にしているのにノートンのVPNが強力すぎてAmazonやNetflixが見えない時の対処法を教えます、答えP2Pに最適な通信にするだけで見れるようになります. 自分はAmazonやNetflixは […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
オン, オンオフ, セキュリティ, ノートン, ブラウザ, よう, 仕事, 使用, 切り分け, 対処, 強力, 必要, 明日, 最適, 答え, 自分, 若干, 設定, 通信, 速度, 除外,

ギリまで使うと思うものの続き、MacBook Proを見てきました、30ー32万円する.
2025.08.01
おはようございます.ギリまで使うと思うものの続き、MacBook Proをケーズデンキに行って見てきました、自分がほしいスペックのマックブックプロは30ー32万円する事が判明.正直なところ高いなと思う…昔の手 […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
イメージ, お金, キリ, ケーズデンキ, スペック, ところ, ブック, プロ, マック, マックブックプロ, もと, もの, リスク, ロボプロ, 予想, 以上, 元本, 入金, 判明, 半年, 口座, 可能, 合計, 場合, 差額, 年利, 強度, 必要, 感じ, 手取り, 投資, 明日, 普通, 最大, 月数, 期間, 正直, 毎月, 目標, 簡単, 結構, 考え, 自分, 衝動, 評価, 貯金, 購入, 運用, 達成, 適当, 金額,
チャットワークのAPIを使ってみました.プロンプトでほぼ書いています.
2025.07.13
おはようございます.チャットワークのAPIを使ってみました.プロンプトでほぼ書いたコードになります、チャットGPTの無料版にリファレンスのURLリンクとPHPのクラス化、リターンに$thisで返却出来る所は$thisを使 […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
```, クラス, コード, コスト, これ, スマート, ソース, それ, チャット, テスト, プロンプト, モンキー, よう, リターン, リファレンス, リンク, ワーク, 下記, 人工, 今回, 使用, 出力, 削減, 動作, 土台, 場合, 必要, 指示, 新規, 明日, 時間, 最初, 案件, 無料, 現場, 生成, 知能, 短縮, 確実, 自分, 返却, 開発, 間違い,

AI時代のマーケティング激変に備えよグーグル検索の60%がクリックされない
2025.07.05
おはようございます.先日、自分が言っていた事は間違いなかったんだなって下記の動画を見て思いました.これから先、SNSとAIを駆使しないと集客出来ない時代になるということですね.要するに検索というものは廃れていくということ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
)。, アカウント, アンサーサイト, いた事, ウェブサイト, エージェント, カスタマーサービス, カスタマーサポート, こと, コンテンツ, コンバージョン, サイト, サポート, サンフランシスコ, ため, ダメージ, チケット, チャネル, ツール, つながり, ティア, デモ, トイウコト, ドラフト, ニュースレター, パーソナライズ, ビジネス, ブログトラフィック, ベース, ポッドキャスト, マーケティング, マップ, メール, もの, ヤミニ, ヤミニ・ランガン, ユーザー, よう, ロード, 一部, 下記, 中心, 主導, 人々, 人員, 人間, 仕事, 以下, 企業, 会議, 体験, 作成, 個人, 側面, 先日, 内容, 分析, 分野, 削減, 効率, 動画, 可能, 台頭, 向上, 問題, 営業, 回答, 変化, 変革, 多く, 多様, 対応, 対面, 導入, 平均, 強化, 強調, 影響, 従来, 必要, 必見, 情報, 意図, 成功, 戦略, 担当, 拡大, 拡張, 提供, 支援, 明日, 時代, 最後, 最適, 検索, 業務, 概要, 活用, 浸透, 減少, 満足, 準備, 焦点, 特定, 現状, 生産, 直接, 社内, 積極, 維持, 職種, 自分, 自動, 自動的, 自身, 製品, 要点, 解決, 解説, 言及, 記録, 訪問, 設定, 調査, 質問, 転換, 迅速, 通り, 通用, 通話, 達成, 適応, 開発, 間違い, 集客, 顧客, 駆使,

Llama-3-ELYZA-JP-8Bとは何か?モデルという奴です.
2025.07.03
おはようございます.Llama-3-ELYZA-JP-8Bは、MetaのLlama 3(8Bパラメータ)をベースに、日本語の指示応答能力を強化するためELYZAがファインチューニングした日本語特化型の大規模言語モデルです […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
カーソル, グラボ, クン, こと, これ, ため, データ, ディビン, トー, パターン, パラメータ, ファインチューニング, プログラム, プロンプト, ベース, モデル, もの, よう, ループ, ルール, 一番, 予測, 今回, 仕組み, 入力, 回答, 回避, 場合, 変換, 学習, 強化, 影響, 必要, 応答, 指示, 数学, 既存, 日本語, 明日, 無限, 生成, 発生, 能力, 自分, 規模, 言語, 計算, 貧弱, 軽量, 離脱, 食い,

AIで今後どうなるだろうな.自然言語処理で指示出し出来てきた今日.
2025.07.01
おはようございます.何だか梅雨明けした休日にGeminiCliでコードを生成しています.仕事ではまだ自分はChatに分からない事を質問するぐらいの事しかしていないのだけども絶対にCliなどで作業すると時間短縮になるのは間 […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
あんま, イメージ, オープン, お金, カーソル, グラフィック, グラボ, コード, こと, コパイロット, ソース, そう, それ, たま, デビィン, とき, ところ, どちら, ビックテック, ボード, みたい, モデル, ローカル, 今後, 仕事, 休日, 余裕, 作業, 使用, 優秀, 問い, 学習, 容量, 導入, 当たり前, 必要, 感じ, 技術, 投資, 推奨, 提供, 明け, 明日, 時代, 時間, 有料, 梅雨, 業界, 機械, 無料, 環境, 生成, 短縮, 移り変わり, 端末, 絶対, 自分, 規模, 言語, 資金, 質問, 開発, 間違い,