@Blog
過去の蓄積を見るために書く日記.

記事の検閲はこの日本でも行われているだろうな.
2025.09.06
おはようございます.記事の検閲はこの日本でも行われている、公にはそれは知られてはいない気がしますが.さてネット検閲の厳しい国の代表的な国が中国です、国に文句が言えないらしいぐらい厳しいらしいですね、実際どうなのかは分から […]
 著者名
@taoka_toshiaki
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
アクセス, いくつ, イラン, インターネット, ウェブサイト, ウクライナ, オンライン, グレート・ファイアウォール, こと, これら, コンテンツ, サービス, システム, そのもの, それ, ネット, ネットワーク, フリーダム・ハウス, ブロック, ミャンマー, メディア, もの, ユーザー, よう, ランキング, ロシア, 一般, 不都合, 世の中, 世界, 中国, 事業, 人権, 代表, 以降, 体制, 何れ, 侵害, 侵攻, 共通, 利用, 制限, 削除, 北朝鮮, 厳格, 参考, 可能, 団体, 国々, 国内, 国境, 国家, 国民, 国際, 報告, 場合, 多く, 強化, 情報, 感じ, 把握, 措置, 政府, 政権, 文句, 旅行, 日本, 明日, 映画, 最新, 検閲, 権利, 機関, 毎年, 活動, 海外, 添付, 物事, 特定, 状況, 独立, 発表, 監視, 管理, 統制, 自分, 自由, 西側, 要求, 規模, 言論, 記事, 記者, 評価, 調査, 諸国, 軍事, 通信, 運用, 遮断, 重要, 頻繁,

AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでも.
2025.06.22
おはようございます.AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでもなくローカルPCでそこら辺に落ちているLlamaモデルを持ってきてチューニングすれば何とかなるじゃねぇという思いに至った. […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
```, ;;), )。, アウト, アシスタント, アダプター, あたり, アップ, あなた, いくつ, ウォーム, エポック, エラー, エントリ, オープン, オプティマイザ, お金, クラウドサービス, グループ, クン, ゲーミング, コード, コア, ここ, こと, コミュニティ, コメント, これ, サイズ, サンプリング, サンプル, シーケンス, スクリプト, スケーリング, スケジューラー, スタイル, ステップ, スペック, すべて, ソース, そこら, タイプ, ダウンロード, タスク, ため, チューニング, ツール, データ, データセット, テーマ, ディレクトリ, テキスト, デバイス, デフォルト, トー, トークナイザー, とき, どれ, トレーナー, ドロップ, バイアス, パス, バッチ, パディング, パラメータ, バランス, ファイル, ファイルサイズ, ファインチューニング, ファインチューニングコード, フリーズ, プロ, プロンプト, マシン, マッピング, メモリ, モード, モデル, もの, ユーザー, よう, ライター, ライブラリ, ラベル, ランク, リモート, レベル, レポート, ローカル, ロード, ログ, 一般, 一部, 上記, 不要, 世界, 世界中, 並み, 並列, 予算, 付与, 以下, 以降, 企業, 使い, 使用, 係数, 保存, 個人, 優秀, 入力, 公開, 共有, 具体, 処理, 出力, 分割, 分散, 分野, 初期, 利点, 利用, 制御, 削減, 削除, 創造, 加速, 助け, 効率, 動作, 勾配, 十分, 参考, 反映, 可能, 向上, 味方, 因果, 場合, 多様, 夢物語, 大幅, 大量, 失敗, 学習, 完了, 完全, 完璧, 実現, 実行, 実質, 寄与, 対応, 専門, 導入, 少量, 工夫, 希望, 常識, 強力, 形式, 必要, 思い, 性能, 手元, 手法, 技術, 抜群, 指定, 指示, 挿入, 推奨, 推論, 提供, 整形, 新た, 方法, 日々, 明日, 明確, 明示, 時代, 時間, 最大, 最新, 最適, 有効, 未知数, 本格, 格段, 格納, 構築, 様々, 比率, 民主, 活用, 活発, 消費, 混合, 済み, 温度, 準備, 無効, 無料, 特定, 特権, 現実, 理由, 環境, 生成, 発生, 登場, 的確, 相性, 短時間, 確認, 秘訣, 移動, 程度, 管理, 節約, 精度, 終了, 結合, 結果, 続行, 能力, 自体, 自分, 自動的, 蓄積, 表現, 言語, 計算, 記事, 設定, 許可, 調整, 費用, 軽量, 追加, 通常, 適用, 選択, 重み, 重要, 量子, 開始, 開発, 関数, 閾値, 非常, 高速, 高額, 魅力,

一言感想、欲望の資本主義メタバースの衝撃デジタル経済!
2022.09.19
おはようございます。台風が何事もなく通り過ぎるのを祈りながら日曜日のお昼に書いています✍。 8月31日頃に「欲望の資本主義2022夏メタバースの衝撃デジタル経済のパラドックス」というNHK:BSで放送されていたものを昨日 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
10, 120, 2022, 31, 5, 8, bs, NHK, オンデマンド, お昼, スマホ, それぐらい, テクノロジー, デジタル, バース, パラドックス, ペイ, メタ, もの, ヲタク, 一, 一般, 一言, 主義, 主観, 事, 今, 何事, 先, 出口, 単品, 印象, 台風, 夏, 大人, 子供, 対応, 後, 感想, 放送, 日曜日, 昨日, 時間, 最初, 欲望, 浸透, 経済, 自分, 衝撃, 視聴, 話, 販売, 資本, 購入, 迷走, 頃,
未来は不確定で予想がつかないけれどブレイクスルーは🤐
2022.09.05
こんにちは、基本情報処理の動画を垂れ流しながらコードを書いています。 さて、今日は未来の話です。未来は不確定で予想がつかないけれどブレイクスルーは必ず起きる。これはどんな分野でもそうだと感じています。今、複雑なことは人で […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, Google, Midjourney, アート, コード, こと, これ, ジャーニー, スマホ, スルー, ツール, つい, デジタル, ブレイク, ミッド, ロボット, 一般, 不確定, 予想, 人, 人々, 人工, 今, 今日, 仕事, 優秀, 先, 入力, 分野, 動画, 基本, 情報処理, 数十, 日, 最近, 未来, 民主化, 登場, 知能, 組み合わせ, 絵, 自分, 自然, 複雑, 言葉, 言語, 話, 話題, 転換期, 道具, 開発,

映画、キングダム2 遥かなる大地へ:実写化された映画の続編おそらく三部作?
2022.07.01
おはようございます。土曜日は局地的に大雨が30分ほど振りましたよね。 さて、7月15日から一般上映されるキングダム2ですが実写キングダム1は映画館で観てきています。でっ今回、キングダム2が上映されることになっています。 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
1, 15, 2, 30, 7, Cg, HIT, アメリカ, キングダム, こと, これ, そこ, それなり, ところ, どちらか, メッセージ, 一般, 三部作, 上映, 人, 今, 今回, 作品, 判断, 否, 土曜日, 大地, 大雨, 実写, 差, 感じ, 技術, 方, 日本, 映像, 映画, 映画館, 未だ, 機会, 気, 続編, 自分, 観, 警告,

windows11が近々セキュリティ強化されるらしい。
2022.04.11
おはよう御座います。徐々に気温が上がり春って感じになってきましたね。 windows11が近々セキュリティ強化されるらしいのですが、かなり大規模なセキュリティアップデートらしくて、もしかしたら再インストールが必要になって […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
10, 11, Windows, アップデート, インストール, かなり, クラッシュ, セキュリティ, ソフト, それ, パソコン, パブリック, マイクロソフト, もの, ユーザー, リスク, 一般, 事, 今, 何度, 使用, 公開, 危, 大規模, 対応, 対策, 導入, 強化, 必要, 所, 提供, 春, 本当, 正直, 気温, 自分, 話, 誰, 開発者,

プラネテス=惑う人=まどうひと。キタニタツヤ!?
2022.03.14
キタニタツヤさんが歌うプラネテスという曲は良い感じだなって思う今日のこの頃。 さてプログラミングは簡単、でもそれを仕事とすることは難しい。そんなつぶやきがタイムラインに流れてきました。「確かにね」って思いましたがプログラ […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, エンジニア, キタニ, こと, サービス, それ, それぐらい, タイムライン, タツヤ, ひと, ひとり, プラネテス, プログラマー, プログラミング, ボリューム, もの, 一人, 一流, 一般, 三流, 事, 事態, 人, 人工, 今日, 仕事, 会社, 差, 感じ, 技量, 時間, 曲, 最前線, 業界, 殆ど, 知能, 程度, 簡単, 貢献, 開発, 頃,
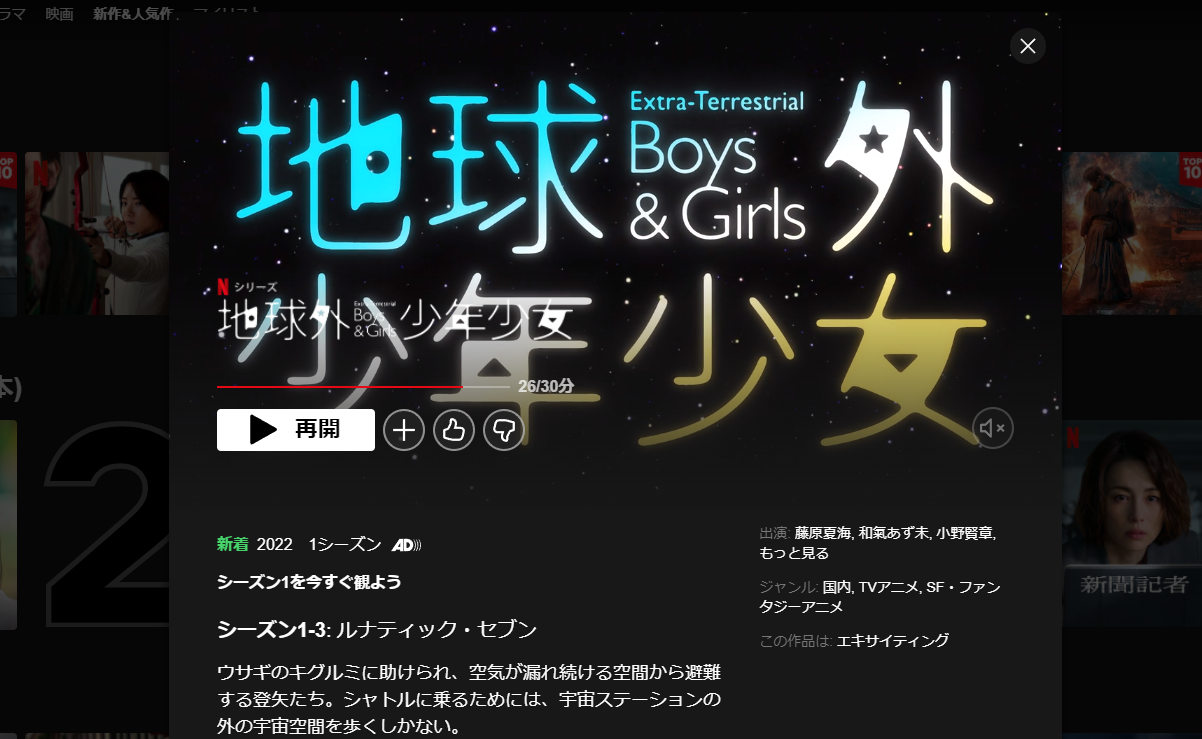
子供向けな地球外少年少女をNetflixで見たけどこれ大人‥。
2022.01.29
どんより曇り空でお外は寒そうです。そんな中、地球外少年少女を観ましたので感想を残しときます。 子供向けかなと思っていた地球外少年少女をNetflixで見たけどこれ大人が見ても、考えさせられる内容になっています。これからデ […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
com, https, Mr, Netflix, watch, www, yMU-xTekqqc, youtube, アニメ, コイル, これ, デジタル, 一気, 一般, 上映, 世界, 中, 予定, 光雄, 全話, 内容, 制作, 前篇, 劇場, 在住, 地方, 地球, 外, 大人, 子供, 子供向け, 存在, 少女, 少年, 後篇, 感じ, 感想, 所, 拡張, 曇り空, 月, 現実, 監督, 磯, 端末, 進化, 都心, 電動, 電脳,

windows11のアップグレードされるまであともう少し?
2021.09.27
今日は朝、ヤシイパークまで自転車で行ってきました、行き帰りで結構な消費カロリーになるらしいですけど未だにあと10kgの体重が落ちません。今年中にはマイナス5kg落としたいなと思っています。 さて、話変わりまして10月の前 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
10, 11, 5, kg, vista, Windows, アップ, エンジニア, カロリー, グレード, ブラウザ, マイナス, ヤシイパーク, ユーザー, 一般, 今回, 今年, 今日, 他, 体重, 初期, 前半, 変更, 好評, 対象者, 成功, 接触, 朝, 未だ, 条件, 気, 浸透, 消費, 独禁法, 結構, 自分, 自転車, 行き帰り, 設定, 話, 選択, 雰囲気, 面,

共同幻想には国家、仕事、お金、法律などなどがある。
2021.08.25
2日続けて晴れ間があり、そろそろ雨も開けそうな予感さえしますが、今日は午後から雨模様です。因みにピンポイント天気が結構な確率で当たることに気付いてそればかり見ています。因みにiPhoneの純正の天気予報もかなりの確率で当 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
2, iPhone, Yahoo, お金, かなり, クエッション, こと, これっと, それ, タイトル, つれ, ピンポイント, フリー, マーク, もの, ランス, レーダー, 一般, 世間, 予報, 予感, 予測, 事, 人, 今日, 仕事, 共同, 共有, 午後, 国家, 地球, 大勢, 天気, 宇宙人, 家, 常識, 幻想, 思想, 晴れ間, 概念, 法律, 無職, 物, 確率, 純正, 結構, 購入, 雨, 雨模様, 頃,

リモートワーク(テレワーク)のこれからどうなるだろうかと?
2021.05.18
リモートワーク(テレワーク)のこれからどうなるだろうかという疑問を考えていて、最近、この疑問に自分なりの考えの答えが出た。どこかのニュース記事にもあったけど、コロナが終息に向かえばリモートワークは減少していくと思いますが […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
IT, オフィス, これ, コロナ, デジタル, テレ, どこか, ところ, ニュース, リモート, ワーク, 一般, 中小企業, 人, 人材, 今回, 仕事, 企業, 個人, 元, 影響, 待遇, 最近, 殆ど, 減少, 災い, 理由, 疑問, 答え, 終息, 自分, 見解, 記事,

アプリ(APP)を紹介しているYOUTUBER
2020.06.21
スマホのアプリを紹介しているユーチューバー(YOUTUBER)、マメさんが伸びていきそうなので紹介します。何故、伸びそうか?それは声です、紹介が分かりやすいというのも有るのだけど、顔出ししていないYOUTUBERさんは何 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
App, YOUTUBER, アプリ, いろいろ, こちら, これ, スマホ, それ, チャンネル, トーク, マメ, ユーチューバー, ラジオ, 一, 一般, 人, 人気, 今回, 何, 動画, 場合, 声, 大事, 大体, 才能, 最後, 材料, 枠, 玄人, 登録, 知識, 紹介, 自分, 話, 質, 重要, 顔出し,
ホログラムは次世代ディスプレイ!?
2019.12.15
ホログラムは次世代ディスプレイになると思いますが、まずは商業施設などで使われるようになり、15年後ぐらいには一般家庭にもホログラムディスプレイが普及すると思います。 たぶん、まだまだ先の話です、いまの映像はホログラム映像 […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
15, AbV-vzwJJtQ, com, https, watch, www, youtube, いま, オールド, こと, ディスプレイ, テクノロジー, ホログラム, 一般, 世界, 側面, 先, 反面, 可能性, 商業, 境界線, 子供, 家庭, 当たり前, 想像, 施設, 映像, 普及, 曖昧, 次世代, 気, 流行, 現実, 話, 負, 頃,
2015年:砂浜Tシャツアート展/高知県幡多郡黒潮町の入野海岸
2015.05.05
砂浜Tシャツアート展/高知県幡多郡黒潮町の入野海岸へ行ってきました。行きは車で一般道路を通って黒潮町まで行ったのですが、到着するのに三時間ぐらい費やしました。高知市内だと二時間半ぐらいはかかると思います。帰りは高速道路を […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
2015, 4850, アート, ありか, イベント, いま, シャツ, それ, もの, 一, 一般, 三, 主催, 事, 二, 今度, 作品, 価値, 入野, 到着, 半, 土佐, 圧巻, 少し, 市内, 幡多郡, 応募, 思, 時, 桂浜, 海岸, 無数, 片道, 疲労困憊, 発生, 皆さん, 短縮, 砂浜, 美術館, 若干, 費用, 車, 車酔い, 運転手, 道路, 難, 電車, 風, 高知, 高知県, 高速道路, 黒潮町,

ブログが続く人、続かない人の訳(´∀`)、SEOとかそんなの置いとけ。Part2
2015.01.29
?昨日の続き、ブログが続く人はだいたい自分の好きな分野で書いていることが多いです。自分ではパソコンヲタクではないと思っているだけで、たぶん、はたから見ればかなり、パソコンやプログラムに関してはマニアックなところまで知って […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
2, Part, SEO, アップ, アニメ, かなり, ガンダム, こと, ところ, ネタ, パソコン, はた, フィギュア, ブログ, プログラム, マニアック, もの, ヲタク, 一般, 世代, 人, 人はだ, 共通, 分け, 分野, 分類, 向上, 市民, 意味, 昨日, 書, 知識, 系, 美少女, 能力, 自分, 言語, 記事, 訳, 話題,
現場のプロが教えるWEB制作の最新常識をパラ読みして(´Д`)
2014.08.25
現場のプロが教えるをパラ読みしての感想などを書いてみます。 この本ですけども、毎日WEBの技術やデザインの流行をチェックしている方は 然程目新しい内容を書いている本ではないです。 こんな方はおすすめ、Web制作会社に入社 […]
著者名
@taoka_toshiaki
※この記事は著者が30代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
4844363980, asin, jp, web, おすすめ, こと, コレ, これだけ, ため, チェック, デザイン, トコロ, どれぐらい, プロ, マーカー, レベル, 一般, 一通り, 世間, 人, 会社, 入社, 内容, 制作, 前後, 周り, 多め, 常識, 感想, 技術, 技術書, 文章, 方, 最新, 本, 毎日, 流行, 現場, 理解, 知識, 経営, 背景色, 自分, 軸, 部分, 重要, 黄,