story of my life
過去の蓄積を見るために書く日記.
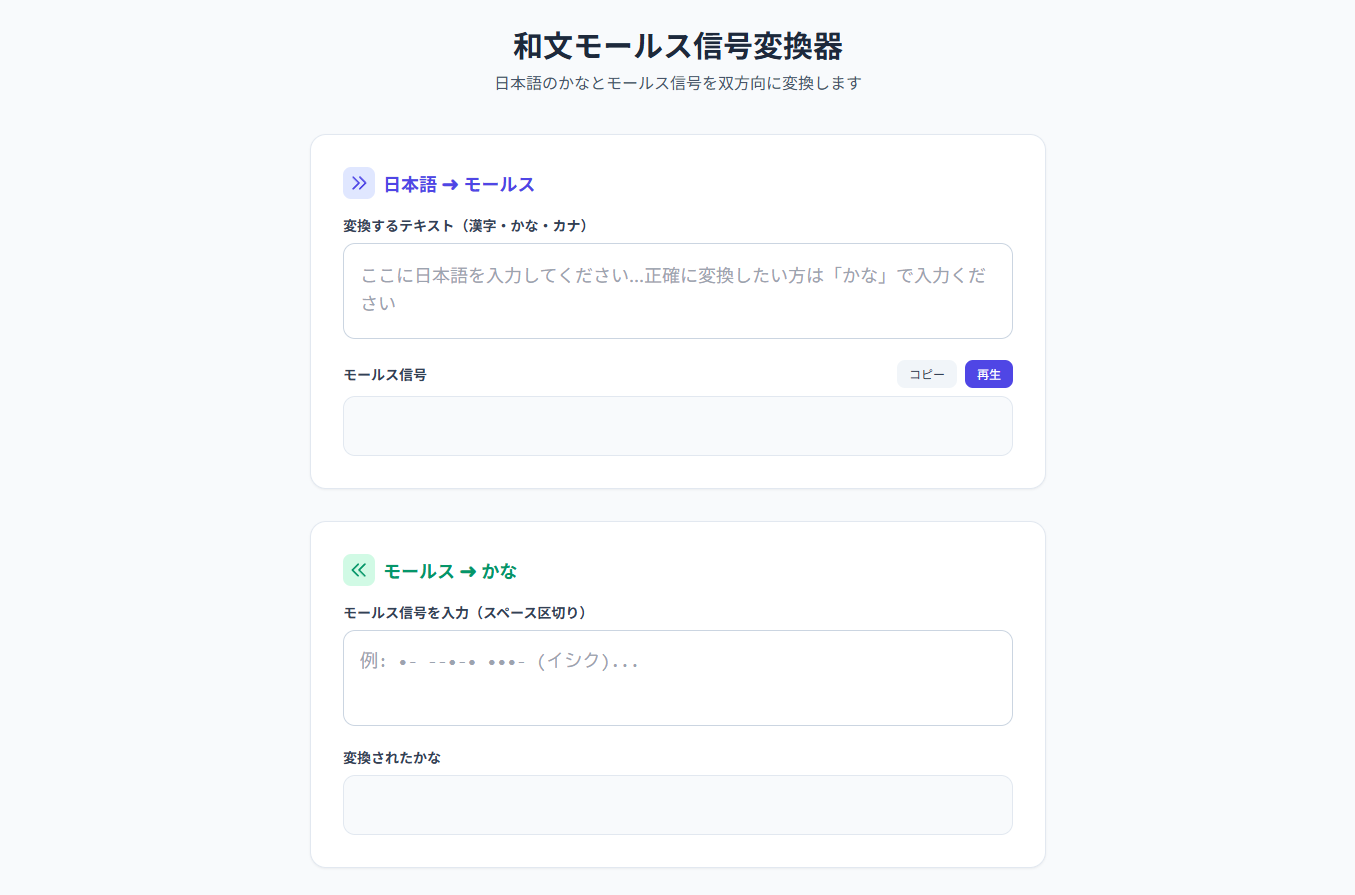
モールス信号変換器を作った話.二番煎じ感
2025.12.22
おはようございます.競合他社とまでは行かないもののモールス信号変換器を作りました、この機能が検索にヒットするまでには少し時間がかかると思います.AI時代にSEOは必要ないなどと言いますが、実際は必要不可欠なんじゃないかな […]
 著者名
@taoka_toshiaki
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
AI, SEO, SNS, いまいち, こと, サイト, そう, そこ, それ, だし, ネット, パターン, ヒット, ひと, ボット, マーケ, マーケティング, みたい, モールス, もの, ランダム, リンク, 一定, 上位, 不可欠, 人達, 他社, 使用, 信号, 効果, 和文, 変換, 変更, 宣伝, 必要, 方法, 明日, 時代, 時間, 最後, 検索, 機能, 活動, 現状, 発信, 競合, 結果, 締め, 自分, 複数, 重要,

さくらレンタルサーバーデータベースをフルバックアップするコード
2025.12.20
おはようございます.アバターは月曜日か火曜日に観に行くつもりでいますがどうなるかは未定です.本日はさくらレンタルサーバーデータベースをごっそり定期的にフルバックアップするコードを作成したのでその話を書いていきます.このコ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
www, アップ, あと, アバター, エラー, クロン, コード, コマンド, コメント, これ, これら, ころ, さくら, そこ, つもり, ところ, パスワード, バックアップ, フルバック, ユーザー, よう, ライン, レンタルサーバーデータベース, 不要, 作成, 使用, 出力, 削除, 可変, 国家, 場合, 変更, 定期, 実行, 必要, 明日, 月曜日, 未定, 本日, 注意, 火曜日, 環境, 県庁, 結果, 結構, 自由, 自身, 設定, 試験, 辺り, 追伸, 重要, 高知,

息抜きの続き、昨日の続きの記事.
2025.09.26
おはようございます.今まで蓄積の為に記事を書いていたのだけど、少し記事をちゃんと書いてみようと思っています.思っているだけで写真を撮るのを今年から始めてみようと言いつつあまり写真も撮ってないように続くか宣言したことがどう […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
Tanaka, Tokimaru, youtube, きっかけ, こと, サン, それら, タイプ, チャンネル, ヒット, まま, ユーチューブ, よう, 今年, 内容, 写真, 宣言, 応援, 成功, 明日, 練習, 自分, 蓄積, 記事, 重要,

記事の検閲はこの日本でも行われているだろうな.
2025.09.06
おはようございます.記事の検閲はこの日本でも行われている、公にはそれは知られてはいない気がしますが.さてネット検閲の厳しい国の代表的な国が中国です、国に文句が言えないらしいぐらい厳しいらしいですね、実際どうなのかは分から […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
アクセス, いくつ, イラン, インターネット, ウェブサイト, ウクライナ, オンライン, グレート・ファイアウォール, こと, これら, コンテンツ, サービス, システム, そのもの, それ, ネット, ネットワーク, フリーダム・ハウス, ブロック, ミャンマー, メディア, もの, ユーザー, よう, ランキング, ロシア, 一般, 不都合, 世の中, 世界, 中国, 事業, 人権, 代表, 以降, 体制, 何れ, 侵害, 侵攻, 共通, 利用, 制限, 削除, 北朝鮮, 厳格, 参考, 可能, 団体, 国々, 国内, 国境, 国家, 国民, 国際, 報告, 場合, 多く, 強化, 情報, 感じ, 把握, 措置, 政府, 政権, 文句, 旅行, 日本, 明日, 映画, 最新, 検閲, 権利, 機関, 毎年, 活動, 海外, 添付, 物事, 特定, 状況, 独立, 発表, 監視, 管理, 統制, 自分, 自由, 西側, 要求, 規模, 言論, 記事, 記者, 評価, 調査, 諸国, 軍事, 通信, 運用, 遮断, 重要, 頻繁,

これからはAIとマーケティングが出来ないと売れない時代.ブランドの作り方なんだろうね.
2025.08.24
おはようございます.これからはAIとマーケティングが出来ないと売れない時代(バーチャルヒューマン).ブランドの作り方なんだろうねと思います、下記と同じものをAIで複製してもマーケティングが上手く出来ないとおそらくフォロワ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
アカウント, キャラクター, こと, サン, そう, それ, ツール, なん, バーチャル, ヒューマン, フォロワー, ブランド, マーケティング, もの, よう, 一つ, 下記, 今日, 作り方, 使用, 個性, 共感, 制作, 大事, 大衆, 当たり前, 意味, 戦略, 手作業, 技術, 明日, 映像, 時代, 生成, 経験, 結局, 複製, 評価, 重要,

昭和の営業、数撃ちゃ当たる的なのは令和では苦笑い、毎日更新のブログとかw
2025.08.13
おはようございます.YOUTUBE動画を先日みました.その中で昭和の営業、数撃ちゃ当たる的なのは令和では苦笑い、毎日更新のブログとかwらしいと語っていた人がいたのです.今は構造を考えて売るや集客するのが当たり前.いやーそ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
あと, いま, こと, これ, サイト, サン, そこ, タグ, テコ入れ, ハッシュ, ピーク, フォロワー, ブログ, ユーザー, 一つ, 人々, 供給, 先日, 動画, 営業, 図式, 大事, 好き, 当たり前, 感じ, 戦法, 明日, 昭和, 更新, 最近, 構造, 毎日, 理解, 確か, 自分, 苦労, 苦笑い, 訪問, 認知, 週間, 重要, 閑古鳥, 集客,

AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでも.
2025.06.22
おはようございます.AIで記事を学習して新たな記事を生み出すにはお金が必要だと思っていたがそうでもなくローカルPCでそこら辺に落ちているLlamaモデルを持ってきてチューニングすれば何とかなるじゃねぇという思いに至った. […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
```, ;;), )。, アウト, アシスタント, アダプター, あたり, アップ, あなた, いくつ, ウォーム, エポック, エラー, エントリ, オープン, オプティマイザ, お金, クラウドサービス, グループ, クン, ゲーミング, コード, コア, ここ, こと, コミュニティ, コメント, これ, サイズ, サンプリング, サンプル, シーケンス, スクリプト, スケーリング, スケジューラー, スタイル, ステップ, スペック, すべて, ソース, そこら, タイプ, ダウンロード, タスク, ため, チューニング, ツール, データ, データセット, テーマ, ディレクトリ, テキスト, デバイス, デフォルト, トー, トークナイザー, とき, どれ, トレーナー, ドロップ, バイアス, パス, バッチ, パディング, パラメータ, バランス, ファイル, ファイルサイズ, ファインチューニング, ファインチューニングコード, フリーズ, プロ, プロンプト, マシン, マッピング, メモリ, モード, モデル, もの, ユーザー, よう, ライター, ライブラリ, ラベル, ランク, リモート, レベル, レポート, ローカル, ロード, ログ, 一般, 一部, 上記, 不要, 世界, 世界中, 並み, 並列, 予算, 付与, 以下, 以降, 企業, 使い, 使用, 係数, 保存, 個人, 優秀, 入力, 公開, 共有, 具体, 処理, 出力, 分割, 分散, 分野, 初期, 利点, 利用, 制御, 削減, 削除, 創造, 加速, 助け, 効率, 動作, 勾配, 十分, 参考, 反映, 可能, 向上, 味方, 因果, 場合, 多様, 夢物語, 大幅, 大量, 失敗, 学習, 完了, 完全, 完璧, 実現, 実行, 実質, 寄与, 対応, 専門, 導入, 少量, 工夫, 希望, 常識, 強力, 形式, 必要, 思い, 性能, 手元, 手法, 技術, 抜群, 指定, 指示, 挿入, 推奨, 推論, 提供, 整形, 新た, 方法, 日々, 明日, 明確, 明示, 時代, 時間, 最大, 最新, 最適, 有効, 未知数, 本格, 格段, 格納, 構築, 様々, 比率, 民主, 活用, 活発, 消費, 混合, 済み, 温度, 準備, 無効, 無料, 特定, 特権, 現実, 理由, 環境, 生成, 発生, 登場, 的確, 相性, 短時間, 確認, 秘訣, 移動, 程度, 管理, 節約, 精度, 終了, 結合, 結果, 続行, 能力, 自体, 自分, 自動的, 蓄積, 表現, 言語, 計算, 記事, 設定, 許可, 調整, 費用, 軽量, 追加, 通常, 適用, 選択, 重み, 重要, 量子, 開始, 開発, 関数, 閾値, 非常, 高速, 高額, 魅力,

お金の本 図解だからわかると貧乏人はお金持ちをパラめくして
2025.06.21
おはようございます.「お金の本 図解だからわかる」と「貧乏人はお金持ち」を電子書籍で読んでみて率直にひろゆき氏が書いた「お金の本 図解だからわかる」が読みやすい、逆に貧乏人はお金持ちは読みづらい、何故か過去の歴史のウンチ […]
著者名
@taoka_toshiaki
※この記事は著者が40代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
!」, アップデート, あと, アドバイス, イラスト, うんちく, おすすめ, お金, グローバル, ゴースト, コスパ, こと, サザエさん, サラリーマン, サン, システム, シンプル, ストレス, ソシャゲ, それぞれ, ターゲット, タイトル, ため, チャン, どちら, どれ, ひろ, ファイナンス, フリーエージェント, マイクロ, メンタル, もの, ゆき, よう, リボ, レベル, 一刀両断, 一家, 一貫, 不可欠, 不安, 不幸, 世界, 主張, 主義, 予備, 人生, 仕組み, 以下, 企業, 会社, 会計, 体系, 使い方, 依存, 保護, 保険, 優遇, 具体, 内容, 出版, 分野, 利用, 利益, 制度, 加筆, 動画, 博之, 合法, 啓発, 図解, 国家, 基本, 変化, 大切, 大胆, 失敗, 宝くじ, 実践, 対応, 専門, 崩壊, 工夫, 常識, 幸せ, 従来, 心掛け, 情報, 意見, 感じ, 戦略, 所得, 手取り, 技術, 投資, 指摘, 措置, 提案, 提示, 方法, 明日, 明確, 時代, 時間, 書籍, 最大, 最新, 最適, 本書, 栄養剤, 楽園, 模索, 正式, 歪み, 歴史, 法人, 法律, 活用, 無税, 無駄遣い, 特徴, 状況, 独立, 率直, 現代, 現状, 理解, 生き方, 生命, 生活, 疑問, 発想, 直感, 相手, 知識, 示唆, 社会, 社長, 税制, 税理士, 税金, 端的, 競争, 箇所, 管理, 終焉, 終身, 経済, 経験, 結婚, 考え方, 自分, 自己, 自由, 自身, 著者, 融資, 行動, 西村, 視点, 解消, 解説, 記載, 設立, 評判, 負担, 貧乏, 貧乏人, 資本, 資金, 購入, 起業, 通り, 運用, 過去, 道具, 違い, 選択, 部分, 重要, 金利, 金持ち, 関係, 雇用, 電子,

休みの日はアクセス数が少ないのを打壊したい人いる!?
2022.11.04
おはようございます、昨日は文化の日でお休みでしたね🫠。 アクセス数ゼロでも毎日のようにブログを書き続けて今のところ、二桁止まりですがアクセス数を維持しています。たまにプレビュー数だと三桁行く時がありますが、今はあまりです […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
アクセス, あまり, おすすめ, お休み, こと, サイト, たま, ため, ところ, ヒット, プレビュー, ブログ, レベル, 三, 上級, 上級者, 中級, 予想, 事, 二, 二番煎じ, 人, 今, 休み, 個人, 全力投球, 初学者, 技術, 数ゼロ, 文化の日, 日, 昨日, 時, 未来, 検索, 毎日, 流行, 無駄, 知見, 維持, 自分, 記事, 誰, 重要,

ページ無限スクロールの作り方 #インフィニティ#InfinityPageScroll #JavaScript
2022.09.22
おはようございます、台風14号が過ぎ去ってからいきなり秋模様ですね🫠。 さて、先日ツイートしたページ無限ループが出来るJavaScriptコードを書きました。これを作ろうと思ったキッカケは、自分が運営しているWordPr […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
14, dom, InfinityPageScroll, javascript, WordPress, インフィニティ, キッカケ, コード, こと, これ, サイト, スクロール, それ, ツイート, プラグイン, ページ, ポイント, ループ, 下記, 事, 作り方, 使用, 先日, 利用, 可能, 台風, 変換, 対応, 専用, 巷, 方法, 最下, 模様, 次頁, 無限, 秋, 自, 自作, 自分, 訳, 運営, 部分, 重要,

一部のサービスのアクセス数が極端に増えたことで思うこと。
2022.08.16
おはようございます。今日は3時に起床してみました。たぶん二度寝することになりそうですが🙄。 さて、一部のサービスでアクセス数が極端に増えてたみたいです、昨日の話。基本的に自分は作るまでが楽しくて作ったものは自分では使用し […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
3, Twitter, アカウント, アクセス, アップ, いまいち, こと, このまま, サービス, シェア, ソーシャル, それ, ツール, テスト, バージョン, もの, 一部, 二, 今, 今日, 何処, 使用, 内容, 匿名, 収益, 口コミ, 大体, 年代, 投稿, 方, 昨日, 極端, 殆ど, 比率, 男女, 皆, 継続, 自分, 解析, 話, 質, 起床, 重要,

円安だから。貯金を進めてくるのは悪徳商法?
2022.07.12
おはようございます。NHKのYOUTUBE動画に「一見、悪徳に見えて、ただ貯金を勧めているだけの男たち」という動画あるのだけどアレ円安になってから見ると悪徳業者に見えてしょうがない・・・。 だからといって海外へ投資を進め […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
10, NHK, youtube, アレ, おすすめ, かけ, ここ, コスト, こと, これ, それ, ところ, ドル, わけ, 一見, 万, 事, 事項, 人, 人工, 但し, 何か, 何倍, 使用, 元手, 円安, 利益, 前, 動画, 商法, 地頭, 大事, 学習, 差額, 平均法, 悪徳, 投入, 投資, 投資信託, 指標, 時期, 株取引, 業者, 機械, 注意, 海外, 男, 発表, 知能, 積立, 経済, 自分, 記事, 誰, 貯金, 資金, 追加, 重要,

物体認識ではラズパイが必ず必要でもないとふと思った。
2022.06.24
おはようございます。記事の投稿の時間帯から変えようか悩んでいます。 さて、今日のお題は「物体認識ではラズパイが必ず必要でもないとふと思った。」です。Iot(Internet of Things)で脚光を浴びたのが小さなパ […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
Internet, IoT, Mac, of, te, Things, web, Windows, オープン, お使い, カメラ, これ, ソース, そちら, それ, ため, はい, パソコン, ベース, モデル, ラズ, ラズベリー, 世, 中, 事, 今日, 使用, 可能, 学習, 帯, 必要, 投稿, 接続, 時間, 構築, 機械, 気圧, 温度計, 湿度, 物体, 環境, 脚光, 記事, 記憶, 認識, 重要, 題,

声が洗脳的なあの有名YOUTUBERさん…。
2022.05.18
おはようございます。 声が洗脳的なあの有名YOUTUBERさん、なおきマンさんは聞いているとわかると思いますがなんか洗脳されそうな声ですよね。YOUTUBEで成功するには声がすごく重要、次に顔が大事になると思います。これ […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
youtube, YOUTUBER, アップ, エンタメ, オカルト, お金, ガジェット, かなり, これ, それ, なおき, ネット, マン, もの, リアル, 一部, 人, 今回, 優位性, 先発, 出来, 利益, 効果, 動画, 収益, 声, 大事, 大体, 成功, 投資, 時, 有名, 洗脳, 解説, 話, 都市, 重要, 顔,

PC版、お試し版のポケトーク字幕を使ってみた。良さ気!!
2022.02.03
PC版、お試し版のポケトーク字幕を使ってみました、海外の人とのzoom会議などには役に立つと感じましたね。あと、YOUTUBERにも何気なく良い感じのツールにもなりそうな予感がするものの、YOUTUBEには自動音声字幕と […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
PC, youtube, YOUTUBER, Zoom, お仕事, お試し版, かなり, こと, こんにゃく, サービス, それ, それまで, ツール, トーク, ドラえもん, ぼけ, ほんやく, リアルタイム, 不明, 予感, 交流, 人, 人々, 今, 会議, 価値, 可能性, 字幕, 実現, 役, 必要, 感じ, 所, 技能者, 数, 日本語, 最低, 機能, 気, 海外, 版, 登場, 翻訳, 自分, 自動, 英語, 英語圏, 話, 重要, 音声,

ハミングバード・プロジェクト 0.001秒の男たち実話ベースの映画。
2021.11.15
「ハミングバード・プロジェクト 0.001秒の男たち」を観ました。この映画、予告とは全然違う内容ですね。 ハミングバードは凄く単純なストーリーです、株取引のために最短距離の通信ケーブルを引き巨額の富を得ようという計画・・ […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
0.001, 40, アルゴリズム, お金, ケーブル, ストーリー, それぐらい, ため, ハミングバード, プロジェクト, ベース, ほんと, ラスト, 予告, 人生, 内容, 処理, 出来事, 単純, 取引, 売買, 実話, 富, 巨額, 映画, 最短, 株取引, 気持ち, 男, 計画, 距離, 通信, 速度, 重要,

少しjava言語を勉強中。自分の勉強方法はこんな感じになります。
2021.08.18
最近、雨が続いていてあの暑さを忘れかけていますが、いま夏なんですよね。。。天気が回復したら空の良い写真が取れそうな気がします。 さて、先日からjava言語をまともに勉強しだしました、アプリ制作をしながらjavaに触れよう […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
java, php, アプリ, いま, オブジェクト, かなり, こと, これ, スタイル, そちら, とき, ネット, まとも, 今更, 他, 先日, 写真, 制作, 勉強, 参考書, 回復, 基本, 夏, 天気, 実際, 少し, 応用, 感じ, 所, 手, 指向, 方, 方法, 最初, 最後, 最近, 正直, 気, 王様, 空, 自分, 言語, 近道, 重要, 雨, 頃, 題,
為になる対談/エンジニアでない人が聞いても為になると思います。
2021.07.05
凄腕エンジニアの堤 修一さんと凄腕エンジニア、個人開発者TAKUYAさんの対談がとても為になる話でとても良かった。自分にとっては神回ですね?!!!。いろいろとハッとさせられるお話が聞けます、ストーリーテリングの重要性や仕 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
4, TAKUYA, アプリ, いろいろ, エンジニア, お話, こと, ストーリー, ツール, テリング, プログラミング, ボリューム, マーケティング, リリース, 人, 今, 仕事, 修一, 個人, 凄腕, 動画, 堤, 対談, 所, 挑戦, 気持ち, 為, 痛感, 神回, 自分, 視聴, 話, 配分, 重要, 重要性, 開発者, 隗,

図解を描いて解説しているところが意図を感じる。
2021.01.07
図解を描いて解説しているところが意図を感じる。優しい語り口でコロナ禍のことを解説している動画であり、これからのことを解説していることであり。データーサイエンスなどのことを語っていることであり。いろいろな事を安宅和人さんが […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
-sWGQP, 2, 30, 6, AI, com, https, iKms, watch, www, youtube, いち, いろいろ, こと, これ, コロナ, サイエンス, ゼロ, データー, ところ, パート, みんな, 両方, 事, 人々, 人工, 価値, 動画, 和人, 図解, 基礎, 子供, 安宅, 将来, 意図, 未来, 知能, 社会, 禍, 解説, 語り口, 重要,
自己啓発じゃなかった。これからITエンジニアになりたい無垢な人達へ。
2020.09.09
この説明、とても簡潔で分かりやすいじゃないかなと思った。その人というのはマコなり社長さんです。若い人たちは知っているかと思いますが、ユーチューブチャンネル登録者数が78万人もいるエンジニア系社長さんです。 サーバのことか […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
78, IT, いろは, エンジニア, こと, これ, サーバ, スキル, チャンネル, ネット, プログラム, ホリエモン, マコ, もの, ユーチューブ, 万, 世, 中, 人, 今, 内容, 勉強, 啓発, 地頭, 大体, 学校, 学歴, 手, 時代, 本当, 無垢, 登録者, 社会, 社長, 簡潔, 結構, 自己, 若干, 解説, 誤差, 説明, 重要, 頃,
最近のスケジュールわんでい
2020.07.31
最近のスケジュールをご説明します。午前4時か5時には目覚めて、起床と当時にパソコンの電源をオンにします。朝、クラウドのお仕事をチェックして出来そうな仕事をピックアップします。次にニュース記事のチェックに一時間ぐらいかかり […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
3, 4, 5, 6, おやつ, オン, お仕事, お気に入り, クラウド, ゴーサイン, こと, これ, ご説明, サイト, シェア, じぶん, スカウト, スケジュール, たま, チェック, ニュース, パソコン, ハローワーク, ピックアップ, フェイスブック, プログラム, メモ, もの, ワン, 一, 今, 仕事, 付, 作業, 偵察, 動作, 午前, 午後, 地元, 大体, 就職, 当時, 応募, 所, 日, 時間, 最近, 朝, 朝食, 案件, 検証, 毎日, 興味, 記事, 起床, 転職, 重要, 電源, 頃,

アプリ(APP)を紹介しているYOUTUBER
2020.06.21
スマホのアプリを紹介しているユーチューバー(YOUTUBER)、マメさんが伸びていきそうなので紹介します。何故、伸びそうか?それは声です、紹介が分かりやすいというのも有るのだけど、顔出ししていないYOUTUBERさんは何 […]
著者名
@taoka_toshiaki
※この記事は著者が40代前半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
App, YOUTUBER, アプリ, いろいろ, こちら, これ, スマホ, それ, チャンネル, トーク, マメ, ユーチューバー, ラジオ, 一, 一般, 人, 人気, 今回, 何, 動画, 場合, 声, 大事, 大体, 才能, 最後, 材料, 枠, 玄人, 登録, 知識, 紹介, 自分, 話, 質, 重要, 顔出し,
嘘半分のWEB事情、WEBのタブーを書いてみる。
2019.11.29
嘘半分のWEB事情、WEBのタブーを書いてみる。毎日ブログを書けばブログのアクセスアップが出来ますよ。これは半分本当で半分ウソである、いくら短文の投稿を有名人のように毎日書いたとしてもアクセス数はほとんどアップしない。 […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
htaccess, web, アク, アクセス, アップ, いま, ウソ, きっかけ, これ, サーバ, サイト, タブー, ドメイン, パス, ブログ, ほとんど, リダイレクト, ルート, 一, 上, 事情, 何か, 候補, 判断, 半分, 可能性, 嘘, 場合, 投稿, 方法, 有名人, 本当, 検索, 毎日, 現在, 直下, 短文, 記事, 設置, 購入, 運用, 重要, 長文,

ブルーオーシャンとは
2019.11.22
ブルーオーシャンとは、競合のいない市場のことを指す。IT業界はブルーオーシャンではもうない、むしろこれからどんな業種でもIT関係の人がひとりは常駐するような社会に転換していくのではと思っている。 ITの人材がこれから必要 […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
IT, オーシャン, おすすめ, かなり, こと, これ, ひとり, ブルー, プログラミング, 人, 人工, 人材, 今, 今後, 分野, 実際, 少し, 市場, 常駐, 役, 必要, 方, 日, 業界, 業種, 目標, 知能, 社会, 競合, 転換, 部分, 重要, 関係, 需要, 高度,

クローラーするサービスの基礎。
2016.11.19
クローラーするサービスの基礎のソースを載せときます。殆どサイボウズ・ラボの人が書いたコードです。このサンプルソースをそのまま貼り付けても一階層のリンクしか取得できません。再帰処理の部分をコメントアウトしているからです。ち […]
著者名
@taoka_toshiaki
※この記事は著者が30代後半に書いたものです.
Profile
高知県在住の@taoka_toshiakiです、記事を読んで頂きありがとうございます.
数十年前から息を吸うように日々記事を書いてます.たまに休んだりする日もありますがほぼ毎日投稿を心掛けています😅.
SNSも使っています、フォロー、いいね、シェア宜しくお願い致します🙇.
SNS::@taoka_toshiaki
タグ
1, 2, ajax, db, アウト, イコール, うち, エラー, オーバー, クローラー, コード, ここ, こと, コメント, これ, サーバ, サービス, サイボウズ, サンプル, ソース, それ, ため, データ, トイウ, メモリ, ラボ, リンク, 一, 下, 事, 人, 保存, 再帰, 処理, 出力, 判断, 取得, 可能, 基礎, 外部, 大事, 大体, 巡回, 新規, 検索, 機能, 殆ど, 永遠, 注意, 登録, 要素, 部分, 重要, 階層,